

Agent-快速开始
本指南将帮助您快速上手 DataFlow Agent 平台的5个核心功能模块。
安装
git clone https://github.com/OpenDCAI/DataFlow-Agent.git
cd DataFlow-Agent
pip install -r requirements.txt
pip install -e .启动Web界面
python gradio_app/app.py访问 http://127.0.0.1:7860 开始使用
目录
1. 管线推荐
功能概述
根据用户的自然语言描述,自动推荐并生成合适的 DataFlow Pipeline,包括算子选择、参数配置和代码生成。
使用场景
- 快速构建数据处理流程
- 不熟悉具体算子时的智能推荐
- 自动化 Pipeline 生成
输入参数
基础配置
目标描述 (必需)
- 描述您想要实现的数据处理目标
- 示例:
"给我随意符合逻辑的5个算子,过滤,去重!" - 示例:
"对文本数据进行清洗、去重、分类"
输入 JSONL 文件路径 (必需)
- 用于测试 Pipeline 的数据文件
- 格式:每行一个 JSON 对象
- 默认:
{项目根目录}/tests/test.jsonl
Session ID
- 会话标识符,用于缓存和追踪
- 默认:
"default"
API 配置
主要模型配置
- Chat API URL: LLM 服务地址
- 默认:
http://123.129.219.111:3000/v1/
- 默认:
- API Key: 访问密钥
- 模型名称: 如
gpt-4o,qwen-max,llama3等- 默认:
gpt-4o
- 默认:
嵌入模型配置
- Embedding API URL: 嵌入模型服务地址(可选,留空则使用主要 API)
- Embedding 模型名称: 如
text-embedding-3-small
调试配置
- 启用调试模式: 是否启用自动调试和修复
- 调试模式执行次数: 1-10 次,默认 2 次
输出结果
1. Pipeline Code (生成的代码)
# 自动生成的 Python 代码
# 包含完整的 Pipeline 定义和执行逻辑2. Execution Log (执行日志)
- Pipeline 执行过程的详细日志
- 包含每个算子的执行状态
- 错误信息和调试信息
3. Agent Results (Agent 执行结果)
{
"recommender": {...},
"pipeline_builder": {...},
"operator_executor": {...}
}- 各个 Agent 节点的详细执行结果
- 包含推荐的算子列表、构建过程等
使用步骤
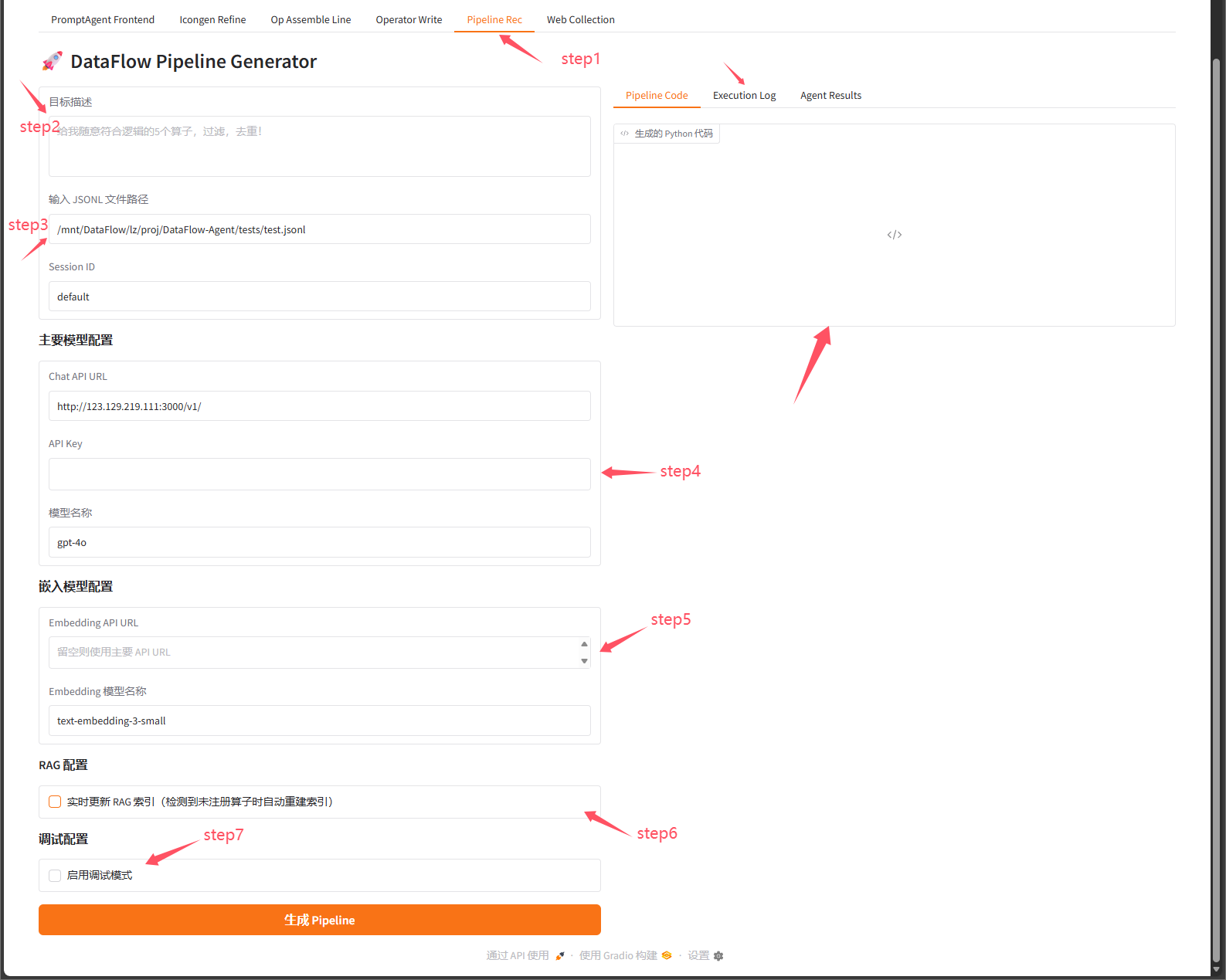
step1:选择管线推荐子页面step2:在"目标描述"框中输入您的需求step3:输入需要处理jsonl文件step4:配置 API 信息(URL、Key、模型)step5:(可选)配置嵌入模型和调试选项step6:选择是否需要自动更新向量索引(如果出现算子不在注册机里,则需要勾选)step7:选择是否使用debug模式(debug模式会自动运行管线,直到自大迭代轮次)step8:右侧 查看生成的代码和执行结果
2. 算子编写
功能概述
根据用户需求自动生成新的 DataFlow 算子代码,包括算子实现、测试代码和调试。
使用场景
- 创建自定义数据处理算子
- 扩展 DataFlow 功能
- 快速原型开发
输入参数
基础配置
目标描述 (必需)
- 描述算子的功能和用途
- 示例:
"创建一个算子,用于对文本进行情感分析" - 示例:
"实现一个数据去重算子,支持多字段组合去重"
算子类别
- 算子所属类别,用于匹配相似算子作为参考
- 默认:
"Default" - 可选:
"filter","mapper","aggregator"等
测试数据文件路径 (JSONL)
- 用于测试算子的数据文件
- 默认:
{项目根目录}/tests/test.jsonl
API 配置
- Chat API URL: LLM 服务地址
- API Key: 访问密钥(留空则使用环境变量
DF_API_KEY) - 模型名称: 默认
gpt-4o
高级配置
- 输出语言:
en(英文) 或zh(中文) - 启用调试模式: 自动执行并修复代码错误
- 最大调试轮次: 1-10 次,默认 3 次
- 输出文件路径: 保存生成代码的位置(可选)
输出结果
1. 生成的代码
# 完整的算子实现代码
class YourOperator(Operator):
def __init__(self, ...):
...
def run(self, dataset, ...):
...2. 匹配的算子
[
{
"op_name": "similar_operator_1",
"similarity": 0.85,
"description": "..."
}
]- 系统匹配到的相似算子列表
- 用作参考和学习
3. 执行结果
{
"success": true,
"output": {...},
"stderr": "",
"stdout": "..."
}- 算子的执行状态
- 输出数据预览
- 错误信息(如有)
4. 调试信息
{
"round": 2,
"input_key": "text",
"available_keys": ["text", "label"],
"stdout": "...",
"stderr": "..."
}- 调试过程的详细信息
- 每轮调试的输入输出
5. Agent 结果
- 各个 Agent 节点的执行详情
- 包含匹配、编写、执行、调试等阶段
6. 执行日志
- 完整的执行过程日志
- 包含所有阶段的详细信息
使用步骤

step1:在"目标描述"中详细说明算子功能step2:选择合适的算子类别,配置 API 信息step3:(可选)启用调试模式以自动修复错误step4:设置debug轮次step5:设置输出jsonl文件路径
3. 手动编排
功能概述
通过可视化界面手动选择和组装算子,构建自定义 Pipeline,支持拖拽排序和参数配置。
使用场景
- 精确控制 Pipeline 结构
- 复用现有算子
- 快速原型验证
- 学习算子使用方法
输入参数
API 和文件配置
- Chat API URL: LLM 服务地址
- API Key: 访问密钥
- 模型名称: 默认
gpt-4o - 输入 JSONL 文件路径: 测试数据文件
算子选择和配置
步骤 1: 选择算子
- 从"算子分类"下拉框选择类别
- 如:
filter,mapper,deduplicator等
- 如:
- 从"算子"下拉框选择具体算子
- 系统会自动显示该算子的参数说明
步骤 2: 配置参数
Prompt Template (可选)
- 如果算子支持 Prompt 模板,会显示下拉选择器
- 选择后自动更新到
__init__()参数中
__init__()参数 (JSON 格式){ "param1": "value1", "param2": 123, "prompt_template": "module.PromptClass" }- 算子初始化参数
- 必须是有效的 JSON 对象
run()参数 (JSON 格式){ "input_key": "text", "output_key": "processed_text", "batch_size": 32 }- 算子运行时参数
- 必须是有效的 JSON 对象
步骤 3: 添加到 Pipeline
- 点击"➕ 添加算子到 Pipeline"按钮
- 算子会被添加到 Pipeline 序列中
步骤 4: 调整顺序
- 在 Pipeline 可视化区域,可以检查算子前后key是否对其
- 系统会自动重新编号
步骤 5: 自动链接
- 系统会自动分析算子间的输入输出关系
- 显示链接状态:
- 🔗 已链接: 输出键成功匹配到下一个算子的输入
- ⚠️ 待处理: 输入为空或未匹配
输出结果
1. 当前 Pipeline (可视化展示)
- 每个算子显示为卡片,包含:
- 步骤编号
- 算子名称
__init__()参数预览run()参数预览- 与上一步的连接状态
2. 当前 Pipeline (JSON 格式)
[
{
"op_name": "TextCleanerOperator",
"init_params": {...},
"run_params": {...},
"_incoming_links": [
{
"input_key": "text",
"value": "raw_text",
"output_keys": ["output"]
}
]
}
]3. 生成的代码
class RecommendPipeline(PipelineABC):
def __init__(self):
super().__init__()
# -------- FileStorage --------
self.storage = FileStorage(
first_entry_file_name="/tmp/test_sample_10.jsonl",
cache_path="dataflow_cache",
file_name_prefix="dataflow_cache_step",
cache_type="jsonl",
)
# -------- LLM Serving (Remote) --------
self.llm_serving = APILLMServing_request(
api_url="http://123.129.219.111:3000/v1/chat/completions",
key_name_of_api_key="DF_API_KEY",
model_name="gpt-4o",
max_workers=100,
)
# -------- Operators --------
self.condor_generator = CondorGenerator(llm_serving=self.llm_serving, llm_serving=self.llm_serving, num_samples=15, use_task_diversity=True)
self.prompted_generator = PromptedGenerator(llm_serving=self.llm_serving, llm_serving=self.llm_serving, system_prompt='分析样本数据,识别与可再生能源相关的关键主题和趋势。', json_schema=None)
self.task2_vec_dataset_evaluator = Task2VecDatasetEvaluator(llm_serving=self.llm_serving, device='cuda', sample_nums=10, sample_size=1, method='montecarlo', model_cache_dir='./dataflow_cache')
def forward(self):
self.condor_generator.run(
storage=self.storage.step(),
input_key='raw_content',
output_key='generated_content_1'
)
self.prompted_generator.run(
storage=self.storage.step(),
input_key='generated_content_1',
output_key='generated_content_2'
)
self.task2_vec_dataset_evaluator.run(
storage=self.storage.step(),
input_key='generated_content_2'
)
if __name__ == "__main__":
pipeline = RecommendPipeline()
pipeline.compile()
pipeline.forward()4. 处理结果数据 (前 100 条)
[
{"text": "processed text 1", "label": "A"},
{"text": "processed text 2", "label": "B"},
...
]5. 输出文件路径
- 处理后数据的保存位置
使用步骤

step1:配置 API 信息和输入文件路径step2:配置APIKeystep3:配置模型step4:选择待处理文件路径step5:选择要组合的算子类别step6:选择要组合的算子step7:如果算子提供了prompttemplate需要选择step8:编辑算子输入和输出key!!step9:运行step10:可以查看组装的代码,和处理结果数据,以及输出文件路径
高级技巧
- 清空 Pipeline: 点击"🗑️ 清空 Pipeline"按钮
- 参数复用: 系统会自动将上一个算子的输出键链接到下一个算子的输入
- 调试: 如果执行失败,检查日志中的错误信息,调整参数后重试
4. 算子复用/提示词优化
功能概述
PromptAgent 前端,用于生成和优化算子的 Prompt 模板,支持多轮对话式改写和测试。
使用场景
- 为算子创建高质量的 Prompt 模板
- 优化现有 Prompt 的效果
- 快速迭代 Prompt 设计
- 生成测试代码和数据
输入参数
运行配置
- Chat API Base URL: LLM 服务地址
- 默认:
http://123.129.219.111:3000/v1/
- 默认:
- Chat API Key: 访问密钥
- Model: 模型名称,默认
gpt-4o - Language: 提示词语言,
zh(中文) 或en(英文)
Prompt 配置
任务描述 (必需)
- 详细描述 Prompt 要完成的任务
- 示例:
"对用户输入的文本进行情感分析,判断是正面、负面还是中性" - 示例:
"将产品描述改写为更吸引人的营销文案"
算子名称 (op-name) (必需)
- Prompt 类的名称
- 示例:
SentimentAnalysisPrompt
输出格式 (可选)
- 指定 Prompt 输出的格式
- 示例:
{ "sentiment": "positive/negative/neutral", "confidence": 0.95 }
参数列表 (可选)
- Prompt 模板需要的参数,用逗号、空格或换行分隔
- 示例:
text, language, style - 示例:
input_text target_audience tone
文件输出根路径 (可选)
- 保存生成文件的目录
- 默认:
./pa_cache
生成后删除测试文件
- 是否在生成后删除测试文件(保留路径占位)
- 默认:启用
输出结果
1. Prompt 文件路径
- 生成的 Prompt 模板文件位置
- 示例:
./pa_cache/prompts/SentimentAnalysisPrompt.py
2. 测试数据文件路径
- 自动生成的测试数据文件
- 示例:
./pa_cache/test_data/test_data.jsonl
3. 测试代码文件路径
- 自动生成的测试代码
- 示例:
./pa_cache/tests/test_prompt.py
4. 测试数据预览
[
{"text": "这个产品真不错!", "language": "zh"},
{"text": "质量太差了", "language": "zh"},
{"text": "还可以吧", "language": "zh"}
]5. 测试结果预览
[
{
"input": {"text": "这个产品真不错!"},
"output": {
"sentiment": "positive",
"confidence": 0.92
}
}
]6. Prompt 代码预览
class SentimentAnalysisPrompt(PromptTemplate):
"""情感分析 Prompt 模板"""
def __init__(self):
super().__init__()
self.system_prompt = "你是一个情感分析专家..."
self.user_prompt_template = "请分析以下文本的情感:{text}"
def format(self, text: str, **kwargs) -> str:
return self.user_prompt_template.format(text=text)多轮改写功能
在右侧对话区域,您可以:
查看初次生成结果
- Prompt 代码
- 测试结果
提出改进建议
- 在对话输入框中描述您希望如何修改
- 示例:
"增加对讽刺语气的识别""输出格式改为只返回 positive/negative/neutral 字符串""添加置信度阈值,低于 0.7 时返回 uncertain"
发送改写指令
- 点击"发送改写指令"按钮
- 系统会根据反馈重新生成 Prompt
迭代优化
- 查看更新后的代码和测试结果
- 继续提出改进建议
- 重复直到满意
清空会话
- 点击"清空会话"按钮重新开始
使用步骤

step1:选择你要复用的带有prompttemplate的算子名称step2:输入你想修改的提示词内容step3:点击“生成提示词模板”step4:右侧预览生成的“输出文件路径,测试数据,提示词模板代码,测试代码”
初次生成
- 配置 API 信息(URL、Key、模型)
- 填写任务描述、算子名称
- (可选)指定输出格式和参数列表
- 点击"生成 Prompt 模板"按钮
- 查看生成的 Prompt 代码和测试结果
多轮优化
- 在右侧对话框中输入改进建议
- 点击"发送改写指令"
- 查看更新后的代码和测试结果
- 重复步骤 1-3 直到满意
使用生成的 Prompt
- 从"Prompt 文件路径"获取文件位置
- 将 Prompt 类导入到您的算子中
- 在算子的
__init__()中指定prompt_template
5. Web Search/数据采集
功能概述
从网络(HuggingFace、Kaggle 等平台)自动采集数据集,并转换为统一格式,支持智能搜索、下载和数据清洗。
使用场景
- 快速构建训练数据集
- 收集特定领域的数据
- 数据集格式转换
- 批量下载和处理
输入参数
采集配置
目标描述 (必需)
- 描述您想要收集的数据类型
- 示例:
"收集 Python 代码示例的数据集" - 示例:
"收集中文对话数据,用于训练聊天机器人" - 示例:
"收集图像分类数据集,包含猫和狗的图片"
数据类别
PT: 预训练数据(Pre-Training)SFT: 监督微调数据(Supervised Fine-Tuning)- 默认:
SFT
数据集数量上限(每关键词)
- 每个搜索关键词返回的数据集数量
- 范围:1-50
- 默认:5
- 注意:仅用于参考,实际数量可能因搜索结果而异
数据集大小范围
- 筛选数据集的大小范围
- 选项:
n<1K: 小于 1000 条1K<n<10K: 1000-10000 条10K<n<100K: 10000-100000 条100K<n<1M: 100000-1000000 条n>1M: 大于 1000000 条
- 默认:
1K<n<10K
下载子任务上限
- 限制最终执行的下载任务数量
- 留空表示不限制
- 用于控制下载规模和时间
最大数据集大小
- 单个数据集的大小上限
- 输入数值后选择单位(B/KB/MB/GB/TB)
- 留空表示不限制
下载目录
- 数据保存的根目录
- 默认:
downloaded_data
提示词语言
zh: 中文en: 英文- 默认:
zh
LLM 配置
- CHAT_API_URL: LLM 服务地址
- 默认:
http://123.129.219.111:3000/v1/chat/completions
- 默认:
- CHAT_API_KEY: 访问密钥
- CHAT_MODEL: 模型名称
- 默认:
deepseek-chat
- 默认:
其他环境配置
- HF_ENDPOINT: HuggingFace 镜像地址
- 默认:
https://hf-mirror.com
- 默认:
- KAGGLE_USERNAME: Kaggle 用户名
- KAGGLE_KEY: Kaggle API 密钥
- TAVILY_API_KEY: Tavily 搜索 API 密钥
RAG 配置
- RAG_EBD_MODEL: 嵌入模型名称
- 默认:
text-embedding-3-large
- 默认:
- RAG_API_URL: RAG 服务地址
- RAG_API_KEY: RAG API 密钥
高级配置(可折叠)
网页采集高级配置
- 下载任务最大循环次数: 1-50,默认 10
- 控制每个下载任务的最大重试次数
- 研究阶段最大循环次数: 1-50,默认 15
- research 阶段的最大循环次数,允许访问更多网站
- 搜索引擎:
tavily/duckduckgo/jina- 默认:
tavily
- 默认:
- 使用 Jina Reader: 是否使用 Jina Reader 提取网页内容
- 默认:启用
- 优点:快速、结构化(Markdown 格式)
- 启用 RAG 增强: 是否使用 RAG 精炼内容
- 默认:启用
- 并行处理页面数: 1-20,默认 5
- 并行处理的页面数量
- 建议:3-10(根据网络和机器性能调整)
- 禁用缓存: 是否禁用 HuggingFace 和 Kaggle 缓存
- 默认:启用
- 启用后使用临时目录,下载后自动清理
- 临时目录: 自定义临时目录路径
- 留空则使用默认临时目录
数据转换高级配置
- 转换模型温度: 0.0-2.0,默认 0.0
- 数据转换时的模型温度参数
- 转换最大 Token 数: 512-8192,默认 4096
- 数据转换时的最大 token 数
- 最大采样长度(字符): 50-1000,默认 200
- 每个字段的最大采样长度
- 采样记录数量: 1-10,默认 3
- 用于分析的采样记录数量
输出结果
1. 执行日志(实时流式输出)
============================================================
开始执行网页采集与转换工作流
============================================================
目标: 收集 Python 代码示例的数据集
类别: SFT
下载目录: downloaded_data
【网页采集配置】
- 搜索引擎: tavily
- 下载子任务上限: 不限制
- 任务最大循环次数: 10
- 研究阶段最大循环次数: 15
- 使用 Jina Reader: 是
- 启用 RAG: 是
- 并行页面数: 5
- 禁用缓存: 是
【数据转换配置】
- 模型温度: 0.0
- 最大 Token 数: 4096
- 最大采样长度: 200
- 采样记录数: 3
数据集大小限制: 不限制
============================================================
2025-01-23 10:00:00 [INFO] 开始搜索数据集...
2025-01-23 10:00:05 [INFO] 找到 15 个候选数据集
2025-01-23 10:00:10 [INFO] 开始下载数据集 1/5...
2025-01-23 10:01:00 [INFO] 数据集 1 下载完成
...
2025-01-23 10:15:00 [INFO] 开始数据转换...
2025-01-23 10:20:00 [INFO] 数据转换完成
流程执行完成!2. 结果摘要
{
"download_dir": "downloaded_data",
"processed_output": "downloaded_data/processed_output",
"category": "SFT",
"language": "zh",
"chat_model": "deepseek-chat",
"max_download_subtasks": null,
"max_dataset_size_bytes": null,
"max_dataset_size_unit": null,
"max_dataset_size_value": null
}输出文件结构
downloaded_data/
├── raw/ # 原始下载的数据
│ ├── dataset_1/
│ │ ├── data.jsonl
│ │ └── metadata.json
│ ├── dataset_2/
│ └── ...
└── processed_output/ # 转换后的统一格式数据
├── combined.jsonl # 合并后的数据
├── train.jsonl # 训练集(如果分割)
├── validation.jsonl # 验证集(如果分割)
└── metadata.json # 元数据信息使用步骤

基础使用
step1:在"目标描述"中详细说明要收集的数据类型step2:选择数据类别(PT 或 SFT)step3:配置数据集数量和大小限制step4:配置 LLM API 信息step5:(可选)配置 Kaggle、Tavily 等服务的密钥step6:点击"开始网页采集与转换"按钮step7:实时查看执行日志step8:等待完成后查看结果摘要step9:在下载目录中查看采集的数据
高级使用
- 展开"⚙️ 高级配置"区域
- 根据需求调整:
- 搜索引擎选择
- 并行处理数量
- 缓存策略
- 数据转换参数
- 执行采集任务
- 根据日志调整参数优化效果
注意事项
API 密钥
- 确保配置了必要的 API 密钥
- Tavily 用于搜索,Kaggle 用于下载 Kaggle 数据集
网络环境
- 如果在国内,建议使用 HuggingFace 镜像
- 调整并行数量以适应网络带宽
存储空间
- 确保有足够的磁盘空间
- 大型数据集可能需要数 GB 空间
执行时间
- 采集过程可能需要较长时间(几分钟到几小时)
- 可以通过限制下载任务数量来控制时间
数据质量
- 启用 RAG 增强可以提高数据质量
- 调整采样参数以平衡质量和速度
常见问题
Q1: API 密钥如何获取?
- OpenAI/GPT: 访问 OpenAI Platform
- Tavily: 访问 Tavily
- Kaggle: 访问 Kaggle Settings
Q2: 如何选择合适的模型?
- 快速原型:
gpt-3.5-turbo,deepseek-chat - 高质量输出:
gpt-4o,claude-3-opus - 中文优化:
qwen-max,deepseek-chat
Q3: Pipeline 执行失败怎么办?
- 检查执行日志中的错误信息
- 确认输入数据格式正确
- 检查算子参数配置
- 启用调试模式自动修复
- 查看 Agent 结果了解详细错误
Q4: 如何提高数据采集质量?
- 使用更精确的目标描述
- 启用 RAG 增强
- 调整数据集大小范围
- 增加采样记录数量
- 使用更强大的 LLM 模型
Q5: 生成的代码可以直接使用吗?
- 管线推荐: 可以直接运行,但建议先在测试数据上验证
- 算子编写: 建议先测试,必要时手动调整
- 手动编排: 生成的代码已经过测试,可以直接使用
- Prompt 模板: 建议多轮优化后再用于生产环境