框架设计
框架设计
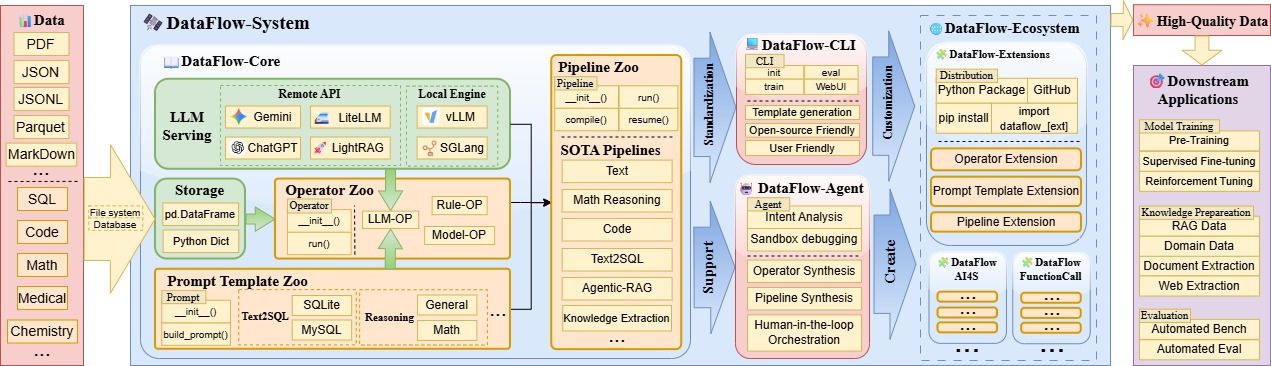
Dataflow的框架主要数据处理逻辑分为算子层(operator)和流水线(pipeline)层。此外,还有数据管理storage和大模型后端LLMServing等组件共同支持。
此外,为了使用AI辅助数据处理,我们额外添加了Agent for Dataflow模块。该模块可以:
- (1)根据需求编写新的Dataflow算子
- (2)根据需求编排现有Dataflow算子,组成Pipeline。
- (3)通过Agent自动解决数据分析任务。
数据管理
DataFlow目前主要关注于大模型文本数据的处理,为了提高易用性,DataFlow内核通过pandas的DataFrame来作为载体实现读写数据(本质上是以表格形式承载的数据)。因此,DataFlow支持常见的json, jsonl, csv, parquet, pickle等多种文本数据集格式作为输入和输出。并以对DataFrame表增删查改的方式来实现数据的清洗,扩增和评估。
实质上数据集管理的功能由storage类实现,源码位于storage.py。目前框架主要依赖文件系统作为数据读写与缓存的载体,未来会支持数据库系统的读写以支持大量数据的处理。
大模型后端
大批量的数据的扩增,过滤,打分都需要借助大语言模型强大而灵活的语义理解能力。因此,DataFlow提供了LLMServingABC抽象类来统一管理在线/本地大模型,也方便模型在算子间的复用。大模型后端目前主要包括如下类:
LocalModelLLMServing: 使用vLLM或SGLang作为推理后端,在本地GPU部署上述框架支持的大模型作为推理服务。适合轻量用户单机使用。APILLMServing_request: 使用request方式向网络上的大模型服务商的API(比如ChatGPT,Deepseek)发起请求,支持多进程并发请求。同时,适合企业级用户基于Ray等框架在集群部署大模型后,通过本类请求相应API。
DataFlow 算子
算子的定义
DataFlow 算子是对原始数据执行的基本处理单元,通常基于规则、深度学习模型或大语言模型(LLM)实现。以最基础的算子PromptedGenerator为例,该算子功能上模仿大家调用GPT的方式,使用同一个提示词批量处理批量的文字。
 具体逻辑如上图所示,该算子读取原始数据中的问题条目,即
具体逻辑如上图所示,该算子读取原始数据中的问题条目,即Q1、Q2...代表的多条问题,将其批量与用户定义的System Prompt组合后,传给LLMServing进行推理,获得输出的答案,即A1、A2...将上述内容组合为如下格式后,即可完成该算子的任务:
[
{"question":"<Q1>", "Answer": "<A1>"},
{"question":"<Q2>", "Answer": "<A2>"}
...
]算子类的代码风格和定义规范
DataFlow的算子的设计参考了PyTorch的代码风格,易于理解。下方代码块是上述PromptedGenerator算子调用的代码实现:
from dataflow.operators.core_text import PromptedGenerator
prompted_generator = PromptedGenerator(
llm_serving=llm_serving # 传入LLMServing类作为大模型后端,这里省略了该类的定义
)
prompted_generator.run(
storage = self.storage.step(), # 数据管理的类,这里省略的该类的定义
system_prompt = "Please solve this math problem.",
input_key = "problem", # 从Dataframe该字段(列),读入内容
output_key= "solution" # 输出结果到Dataframe的该字段(列)
)Dataflow算子类需要定义如下三个函数:
__init__函数: 初始化必要的设置和超参数;- 如果算子使用了大模型,需要以
llm_serving字段在__init__函数中传参。不允许算子内部自行声明大模型。
- 如果算子使用了大模型,需要以
run函数: 有一个storage形参,和多个key形参作为参数用于确认该算子会读/写数据表Dataframe的哪些列。其余未被涉及的列不会参与算子逻辑。run函数的第一个形参一定是storage,并传入数据管理类,用于实现算子间通信,链接所有算子。run函数中除了storage的形参名称都必须以input_或output_作为前缀,分别代表算子的读入算子的字段和算子输出的字段。run函数中的key形参的值可由用户灵活指定,以适应LLM数据集多变的字段命名方式(比如:question,instruction,human都会用来指代多轮对话中人类的问题)。此时设置为input_key="question",input_key="instruction"或input_key="human"即可实现对于该类数据集的自由读取。run函数内部不应该有除了storage和各种key以外的任何参数。- 如果算子只需读取/写出一个字段,则一般通过
input_key和output_key来指定。 - 如果算子不需要写出字段,则完全没有
output_*这样的形参。 - 如果需要读取/写出多个字段,则一般通过其功能指定形参名,比如
input_question_key,input_answer_key,output_question_quality_key。
get_desc函数,可以直接调用,获得该算子的功能描述,和形参列表描述。可通过对lang形参传zh获得中文描述或en获得英文描述。该功能可以服务于Agent理解算子功能。
算子的分类规范
Dataflow的算子目前设置了两级分类。更多的分类级别可能会带来分类困难,目前实践中认为这样是较为合理的,如果您有更好的分类方式,也欢迎在Issue中做出讨论。
目前Datalfow中算子的一级分类如下:
|-- agentic_rag # Agentic-RAG数据合成
|-- chemistry # 化学相关
|-- conversations # 多轮对话
|-- core_speech # 核心-语音
|-- core_text # 核心-文本
|-- core_vision # 核心-视觉
|-- general_text # 通用-文本
|-- knowledge_cleaning # 知识库清洗(MinerU)
|-- reasoning # 强推理数据
|-- text2sql # 自然语言到SQL
|-- text_pt # 文本-预训练
`-- text_sft # 文本-有监督微调一级分类的分类逻辑为:
core算子: 体现了Dataflow设计理念的核心算子。
- 其他类别的算子或多或少是参考了某个
core算子实现的。core算子可以认为是整个dataflow所有算子逻辑的抽象。或者说是其他算子的一个具象的基类(虽然实际不存在代码上的继承关系)。 core算子理论上必须是数量有限,相对收敛的。- 所以,我们建议所有刚接触Dataflow的用户首先学习了解
core_*前缀分类的算子。 core算子按照模态做了拆分,但统称为core算子。
- 其他类别的算子或多或少是参考了某个
领域算子: 为了实现多种模态,多种领域,多种任务的功能,我们具体的对每一个任务的算子进行了分类。
- 一般来说,领域算子可以看做是对于
core算子的二次封装,领域算子一般都能找到对应的core算子。这些领域算子都可以通过填充core算子的形参来等效替代。 - 领域算子理论上是数量无限的,不收敛的,每一个垂域内部会有无限的评估和生成需求。
- 不过,Dataflow中的领域算子,是为了实现某流水线的最佳表现而保留的所有的必要算子,所以看上去并不“无限”。
- 所以,我们欢迎用户填充
core算子,或自定义新的领域算子,来满足各自的“无限”需求。也欢迎用户尽可能用我们提供的“已知最优”的领域算子快速实现所需功能。
- 一般来说,领域算子可以看做是对于
二级分类的分类逻辑首先会通过文件夹和文件名共同体现,包含如下四个文件夹:
generate: 包含两种范式:- 1)数据条目数量不变,每一个条目出现新的Key,对应value是一段新的长文本。即给每一条数据添加新的信息和字段;
- 算子类一般以
*Generator作为后缀。
- 算子类一般以
- 2)数据条目数量增加,丰富整个数据集的信息量。
- 算子类一般以
*RowGenerator作为后缀
- 算子类一般以
- 1)数据条目数量不变,每一个条目出现新的Key,对应value是一段新的长文本。即给每一条数据添加新的信息和字段;
eval:包含两种范式:- 1)数据条目数量不变,每一个条目出现一个新的字段,可以是分数或者类别作为评估结果;
- 算子类一般以
SampleEvaluator作为后缀。
- 算子类一般以
- 2)数据条目数量和字段值都不变,为整个数据集进行评估,对整个数据集输出一个总的评价指标。
- 算子类一般以
DatasetEvaluator作为后缀。
- 算子类一般以
- 1)数据条目数量不变,每一个条目出现一个新的字段,可以是分数或者类别作为评估结果;
filter:从多条数据条目过滤成少量数据条目,每一个条目内容不变,或者仅多了一个经由eval产生的字段。- 算子类一般以
Filter作为后缀。
- 算子类一般以
refine:数据条目数量不变,每一个条目对于某一个字段进行修改。- 算子类一般以
Refiner作为后缀。 进一步的具体功能
- 算子类一般以
举一些算子的例子:(后续补充具体算子名称)
- generate: 根据问题生成答案;
- eval: 为数学题按照难度打分;为问答对的学科类别进行分类;
- filter: 过滤掉答案不对的条目;
- refine: 去掉文字中的url;去掉文字中的emoji。
DataFlow 流水线(Pipeline)
流水线概览
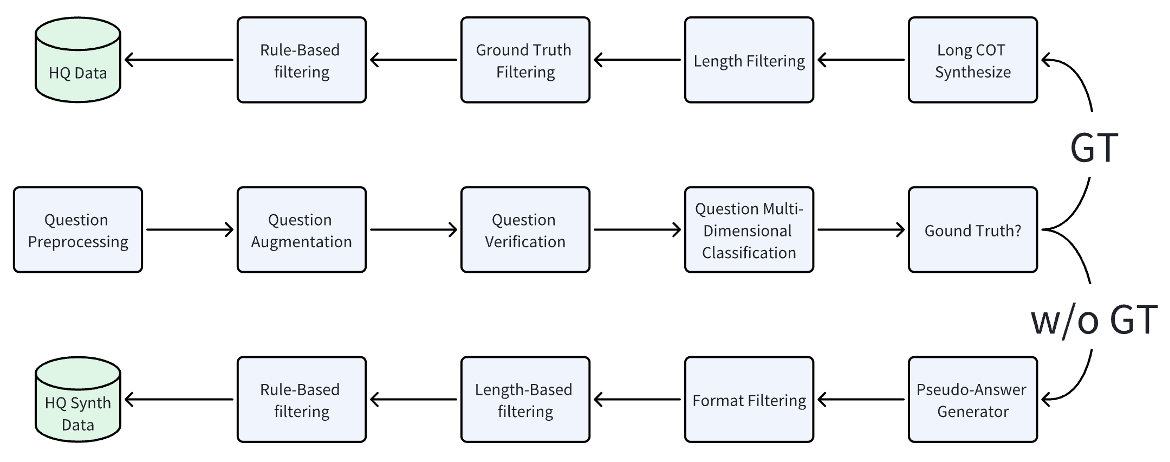
通过组合多种不同算子为流水线(Pipeline),即可实现复杂的数据治理任务。如下面的“强推理数据合成流水线”的示意图所示,每一个矩形单元均可视为一个独立的 DataFlow 算子,用于完成特定的数据加工任务(如扩增、评估、过滤等)。
DataFlow中的流水线一般以如下范式组织算子,整体代码风格仍然向PyTorch看齐,以合成思维链用的Reasoning流水线为例,完整流水线代码如下:
from dataflow.operators.reasoning import (
ReasoningQuestionGenerator,
ReasoningAnswerGenerator,
)
from dataflow.operators.reasoning import ReasoningQuestionFilter, ReasoningAnswerNgramFilter, ReasoningAnswerModelJudgeFilter
from dataflow.utils.storage import FileStorage
from dataflow.serving import APILLMServing_request
from dataflow.core import LLMServingABC
from dataflow.prompts.reasoning.general import (
GeneralQuestionFilterPrompt,
GeneralAnswerGeneratorPrompt,
GeneralQuestionSynthesisPrompt,
AnswerJudgePrompt,
)
class GeneralReasoning_APIPipeline():
def __init__(self, llm_serving: LLMServingABC = None):
self.storage = FileStorage(
first_entry_file_name="../example_data/ReasoningPipeline/pipeline_general.json",
cache_path="./cache_local",
file_name_prefix="dataflow_cache_step",
cache_type="jsonl",
)
# use API server as LLM serving
self.llm_serving = APILLMServing_request(
api_url="http://api.openai.com/v1/chat/completions",
model_name="gpt-4o",
max_workers=30
)
self.question_filter_step1 = ReasoningQuestionFilter(
system_prompt="You are an expert in evaluating mathematical problems. Follow the user's instructions strictly and output your final judgment in the required JSON format.",
llm_serving=self.llm_serving,
prompt_template=GeneralQuestionFilterPrompt()
)
self.question_gen_step2 = ReasoningQuestionGenerator(
num_prompts=1,
llm_serving=self.llm_serving,
prompt_template=GeneralQuestionSynthesisPrompt()
)
self.answer_generator_step3 = ReasoningAnswerGenerator(
llm_serving=self.llm_serving,
prompt_template=GeneralAnswerGeneratorPrompt()
)
self.answer_model_judge_step4 = ReasoningAnswerModelJudgeFilter(
llm_serving=self.llm_serving,
prompt_template=AnswerJudgePrompt(),
keep_all_samples=True
)
self.answer_ngram_filter_step5 = ReasoningAnswerNgramFilter(
min_score = 0.1,
max_score = 1.0,
ngrams = 5
)
def forward(self):
self.question_filter_step1.run(
storage = self.storage.step(),
input_key = "instruction",
)
self.question_gen_step2.run(
storage = self.storage.step(),
input_key = "instruction",
)
self.answer_generator_step3.run(
storage = self.storage.step(),
input_key = "instruction",
output_key = "generated_cot"
),
self.answer_model_judge_step4.run(
storage = self.storage.step(),
input_question_key = "instruction",
input_answer_key = "generated_cot",
input_reference_key = "golden_answer"
),
self.answer_ngram_filter_step5.run(
storage = self.storage.step(),
input_question_key = "instruction",
input_answer_key = "generated_cot"
)
if __name__ == "__main__":
pl = GeneralReasoning_APIPipeline()
pl.forward()目前DataFlow提供了多种预设Pipeline流水线用于完成预定功能。当你熟悉DataFlow框架后,也可以自由搭配现有算子,或设计你自己的新算子来构建适合你数据处理的pipeline。
预编译流水线
上述流水线的“规约”实际相当宽松,__init__函数和forward函数实际上只是两个简单的函数,并没有通过继承任何特殊的基类以对这两个函数做任何额外的检查。
宽松的设计可以便于用户后续实现自己的功能,并且融入自己的业务代码。但是当使用Dataflow-Agent或构建复杂pipeline时,是有必要预先检查各个算子的填入的key进行预先检查的。否则,在执行大量数据和算子时,程序在中间算子才触发一个KeyError的异常退出进程的情况实在令人沮丧。
所以我们提供了一个更有效的compile()函数,来提供对于pipeline的“运行前检查”,未来我们也会对该函数提供更多的技术优化。目前该函数的功能仅局限于检查算子的key填充是否合理,以减少Agent的debug次数。
具体来说,下面是一个Dataflow中Pipeline预编译的例子,该例子实现了将英文输入翻译为中日韩三语输出的流水线,请特别关注高亮的行,这些行实现了预编译的主要逻辑:
# https://github.com/OpenDCAI/DataFlow/blob/main/test/test_autoop_graph.py
from dataflow.pipeline import PipelineABC
from dataflow.operators.core_text import PromptedGenerator
from dataflow.serving import APILLMServing_request, LocalModelLLMServing_vllm, LocalHostLLMAPIServing_vllm
from dataflow.utils.storage import FileStorage
class AutoOPPipeline(PipelineABC):
def __init__(self):
super().__init__()
self.storage = FileStorage(
first_entry_file_name="../dataflow/example/GeneralTextPipeline/pt_input.jsonl",
cache_path="./cache",
file_name_prefix="dataflow_cache_auto_run",
cache_type="jsonl",
)
self.llm_serving = LocalModelLLMServing_vllm(
hf_model_name_or_path="/mnt/public/model/huggingface/Qwen3-0.6B"
)
self.op1 = PromptedGenerator(
llm_serving=self.llm_serving,
system_prompt="Translate following content into Chinese:",
)
self.op2 = PromptedGenerator(
llm_serving=self.llm_serving,
system_prompt="Translate following content into Korean:",
)
self.op3 = PromptedGenerator(
llm_serving=self.llm_serving,
system_prompt="Translate following content into Japanese:"
)
def forward(self):
self.op1.run(
self.storage.step(),
input_key='raw_content',
# output_key='content_CN'
output_key="raw_content"
)
self.op2.run(
self.storage.step(),
input_key='raw_content',
# input_key="raw_content",
output_key='content_JA'
)
self.op3.run(
self.storage.step(),
input_key='raw_content',
output_key='content_KR'
)
if __name__ == "__main__":
pipeline = AutoOPPipeline()
pipeline.compile()
print(pipeline.llm_serving_list)
print(pipeline.llm_serving_counter)
pipeline.draw_graph(port=8081, hide_no_changed_keys=True)
pipeline.forward() # 正常的运行综上,为了实现预编译,需要在Pipeline类中实现如下细节:
- Pipeline类需要继承
dataflow.pipeline.PipelineABC,并在__init__函数中使用super().__init__()来启用必要的修饰。 - 在运行时运行
pipeline.complie(),即可启动编译,会将动态的算子拓扑结构落实为静态图,并提前检测算子逻辑和key逻辑是否正确,即运行前检查。无需等到执行到该算子时才报逻辑错误。- 比如:上面的例子中,我将算子
op3的run的input_key改为raw_input,则理论上数据表中不存在该key,找不到该key,此时执行compile会提前抛出如下异常,可以高效辅助Agent减少debug轮数:
2025-09-23 12:54:36,686 | Pipeline.py - Pipeline - _build_operator_nodes_graph- 133 - DataFlow | WARNING | Processno 1956836 - Threadno 140493607409472 : Key Matching Error in following Operators during pipeline.compile(): - Input key 'raw_inputs' in `op3` (class <PromptedGenerator>) does not match any output keys from previous operators or dataset keys. Check parameter 'input_key' in the `op3.run()`. - 比如:上面的例子中,我将算子
- 编译后,算子拓扑结构会落实为静态图的拓扑结构,执行
pipeline.forward()即可正常执行逻辑。 - 特别的,运行
pipeline.draw_graph()函数可以自动帮你在画布上绘制你当前流水线的拓扑结构。该指令会在指定端口自动呼出浏览器,并提供可以拖拽查看的HTML动态页面,以供用户检查当前流水线代码组织的算子逻辑是否无误。上述案例建立的HTML拓扑图可视化如下: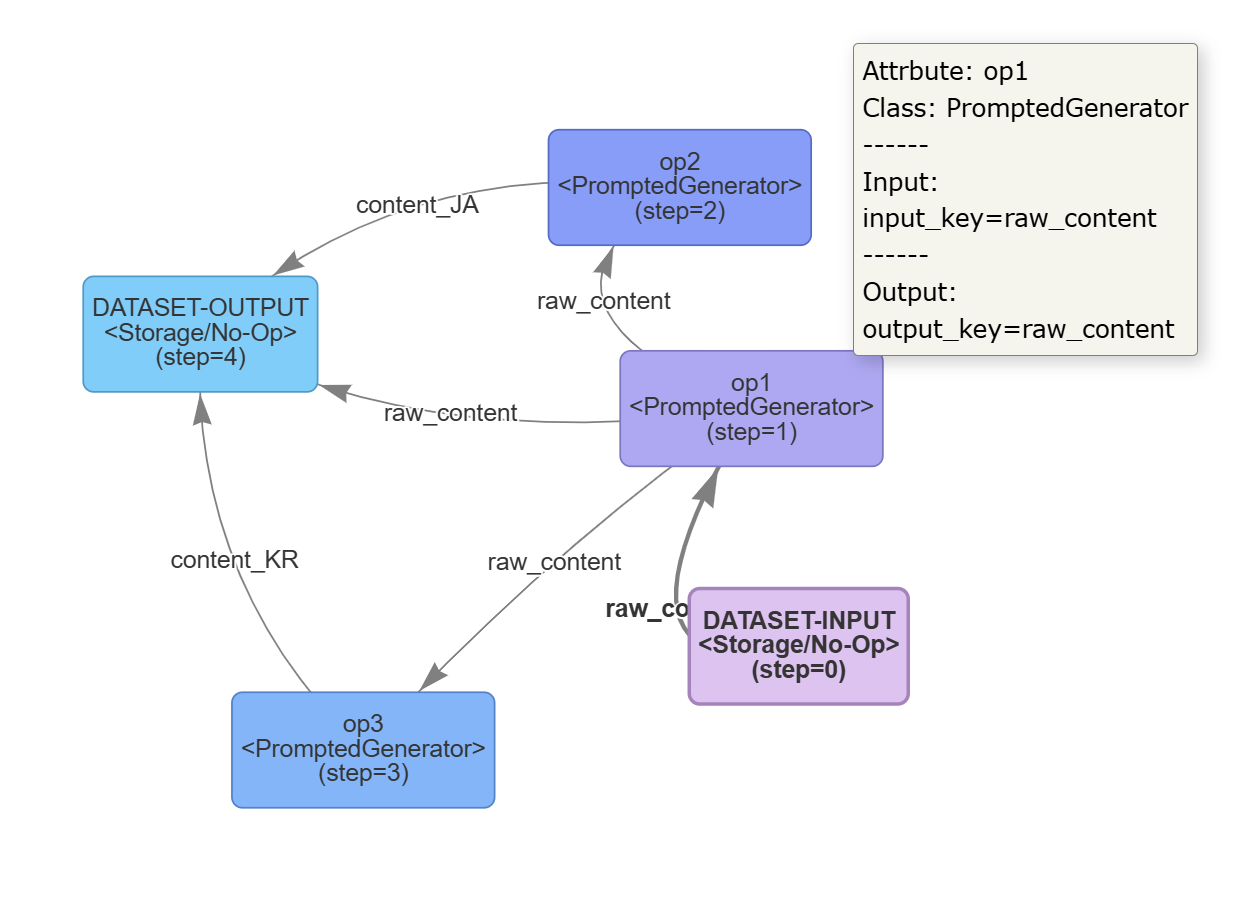
- 每一个节点代表一个算子,或 数据集输入和输出的节点。
- 括号内的
(step=n)即为各个节点的run函数调用的顺序,特别的,算子颜色会根据step从小到大,从紫色到蓝色渐变,以便直观观察。 - 将鼠标停放在算子上,可以看到具体的算子的详细信息。
断点恢复流水线(Resume)
实际调试和开发流水线的过程中可能经常会遇到中间某个算子有bug导致中断的情况。这时就可以借助resume功能跳过前面的算子,从你期望恢复的算子处继续推理整个流水线。
这个功能依赖compile()函数实现,参考如下实现方式:
# https://github.com/OpenDCAI/DataFlow/blob/main/test/test_autoop_graph.py
from dataflow.pipeline import PipelineABC
from dataflow.operators.core_text import PromptedGenerator
from dataflow.serving import APILLMServing_request, LocalModelLLMServing_vllm, LocalHostLLMAPIServing_vllm
from dataflow.utils.storage import FileStorage
class AutoOPPipeline(PipelineABC):
def __init__(self):
super().__init__()
self.storage = FileStorage(
first_entry_file_name="../dataflow/example/GeneralTextPipeline/pt_input.jsonl",
cache_path="./cache",
file_name_prefix="dataflow_cache_auto_run",
cache_type="jsonl",
)
self.llm_serving = LocalModelLLMServing_vllm(
hf_model_name_or_path="/mnt/public/model/huggingface/Qwen3-0.6B"
)
self.op1 = PromptedGenerator(
llm_serving=self.llm_serving,
system_prompt="Translate following content into Chinese:",
)
self.op2 = PromptedGenerator(
llm_serving=self.llm_serving,
system_prompt="Translate following content into Korean:",
)
self.op3 = PromptedGenerator(
llm_serving=self.llm_serving,
system_prompt="Translate following content into Japanese:"
)
def forward(self):
self.op1.run(
self.storage.step(),
input_key='raw_content',
# output_key='content_CN'
output_key="raw_content"
)
self.op2.run(
self.storage.step(),
input_key='raw_content',
# input_key="raw_content",
output_key='content_JA'
)
self.op3.run(
self.storage.step(),
input_key='raw_content',
output_key='content_KR'
)
if __name__ == "__main__":
pipeline = AutoOPPipeline()
pipeline.compile()
pipeline.forward(resume_step=2) # 从index为2的算子开始运行,即op3 #在compile()后,向forward()函数传入resume_step形参,即可从对应的step开始恢复流水线推理,默认从0开始。 这要求之前至少运行到前一个算子,有相应的前一步的*_step_*.json输出作为输入才可以。
DataFlow 提示词和提示词模板(Prompt & Prompt Template)
定义和功能
大模型数据治理,Prompt是重要的构成部分。为了更好的复用算子,我们提供了提示词和提示词模板用于支持算子功能。它们的定义如下:
- 提示词:写死在一个算子内的提示词,一般不会有很明显的替换需求。
- 提示词模板:可能需要传入一些额外信息组成完整提示词的模板;亦或是一个算子为了实现不同功能,通过替换不同提示词模板来满足灵活多变需求的设计。
- 总的来说,提示词和提示词模板对于算子来说,是多对一的映射关系。多个提示词可能会同时或者互斥地支持一个算子的功能。
特别的,即便算子内部只有一个很精简的提示词,且被写死,Dataflow也希望该Prompt能被单独创建一个类,并被注册。这样方便全局查阅提示词和算子的关系,并提供给Agent或者用户作为全局参考,用于写新的提示词组装到对应的算子中。
代码实现
首先,Dataflow所有的提示词和提示词模板放置在./dataflow/prompts路径下,按照对应的流水线名称命名python文件。
无论是提示词还是提示词模板,都需要继承dataflow.core.prompt.PromptABC的实现。
class PromptABC():
def __init__(self):
pass
def build_prompt(self):
raise NotImplementedError
class DIYPromptABC(PromptABC):
def __init__(self):
super().__init__()
def build_prompt(self):
raise NotImplementedError上述二者的区别是:
PromptABC是由DataFlow主仓库中官方开发者提供的所有提示词模板继承的类,会用来严格约束算子和提示词模板的“一对多”的关系,即强制检查一个算子只能输入某些模板。- 当然,如果用户需要自定义一些新的模板时还需要修改官方仓库里的定义,会非常的麻烦,所以
DIYPromptABC是供仓库的用户想自己定义一个相似的,新的提示词模板的基类。继承DIYPromptABC的类,默认可以传入任何带prompt_template形参的模板,不会受到DataFlow系统类型检查的影响。当然,需要用户参考现有的官方提示词模板的传参方式和用法来实现自己的。
整体规约相对简单,所有的提示词和提示词模板只要实现build_prompt函数即可,算子通过调用build_prompt函数来构成需要的提示词。其中__init__和build_prompt函数的形参列表可以根据需要自行设计拓展。
实际的提示词模板定义时,需要通过dataflow.utils.registry下的PROMPT_REGISTRY对提示词模板进行注册:
from dataflow.utils.registry import PROMPT_REGISTRY
from dataflow.core.prompt import PromptABC
@PROMPT_REGISTRY.register()
class DemoPrompt(PromptABC):
'''
The prompt for the answer generator.
'''
def __init__(self):
pass
def build_prompt(self, question: str) -> str:
"""
为给定数学题目生成系统提示信息
"""
prompt = r'''You are helpful agent'''进一步,当提示词被应用于对应算子时,需要通过dataflow.core.prompt下的prompt_restrict装饰器来修饰对应算子类的声明函数。这一步可以在Dataflow中建立算子到Prompt的映射。
from dataflow.utils.registry import OPERATOR_REGISTRY
from dataflow import get_logger
from dataflow.core import OperatorABC
from dataflow.utils.storage import DataFlowStorage
from dataflow.core import LLMServingABC
from dataflow.core.prompt import DIYPromptABC
from dataflow.prompts.reasoning.math import MathQuestionFilterPrompt
from dataflow.prompts.reasoning.general import GeneralQuestionFilterPrompt
from dataflow.prompts.reasoning.diy import DiyQuestionFilterPrompt
from dataflow.core.prompt import prompt_restrict
import re
@prompt_restrict(
MathQuestionFilterPrompt,
GeneralQuestionFilterPrompt,
DiyQuestionFilterPrompt
)
@OPERATOR_REGISTRY.register()
class ReasoningQuestionFilter(OperatorABC):
def __init__(self,
system_prompt: str = "You are a helpful assistant.",
llm_serving: LLMServingABC = None,
prompt_template = MathQuestionFilterPrompt | GeneralQuestionFilterPrompt | DiyQuestionFilterPrompt | DIYPromptABC
):
self.logger = get_logger()
if prompt_template is None:
prompt_template = MathQuestionFilterPrompt()
self.prompt_template = prompt_template
self.system_prompt = system_prompt
self.llm_serving = llm_serving
self.empty_responses_count = 0 # 添加空响应计数器
...这一步会有如下细节,参考上文高亮部分:
prompt_restrict后的函数需要填入该算子所有持有的prompt类。- 如果该算子希望对外暴露可更换的提示词模板供用户填入不同功能的提示词,则算子形参列表中必须有一个字段为
prompt_template并且通过Python类型注解提示用户该位置可填入的选项。 - 如果该算子内部的提示词是写死的,也需要填
@prompt_restrict,但是不用管形参列表。
特别的,当完成prompt_restrict类型注解后,该算子会额外拥有一个成员ALLOWED_PROMPTS,你可以通过如下方式获得该算子可选的提示词或提示词模板,Dataflow的算子也就是通过这样的方式建立了从算子到提示词的“一对多”映射关系。并且prompt_template形参中必须填入这里存在的官方的类,以及用户自定义且继承了DIYPromptABC的新的prompt,DataFlow系统会在算子运行时进行检查。
from dataflow.operators.reasoning import ReasoningQuestionFilter
op1 = ReasoningQuestionFilter()
print(op1.ALLOWED_PROMPTS)得到的输出是:
2025-09-24 16:25:07,928 | registry.py - registry - __getattr__ - 273 - DataFlow | INFO | Processno 1986103 - Threadno 140565043730240 : Lazyloader ['dataflow/operators/reasoning/'] trying to import ReasoningQuestionFilter
(<class 'dataflow.prompts.reasoning.math.MathQuestionFilterPrompt'>, <class 'dataflow.prompts.reasoning.general.GeneralQuestionFilterPrompt'>, <class 'dataflow.prompts.reasoning.diy.DiyQuestionFilterPrompt'>)DataFlow数据统计
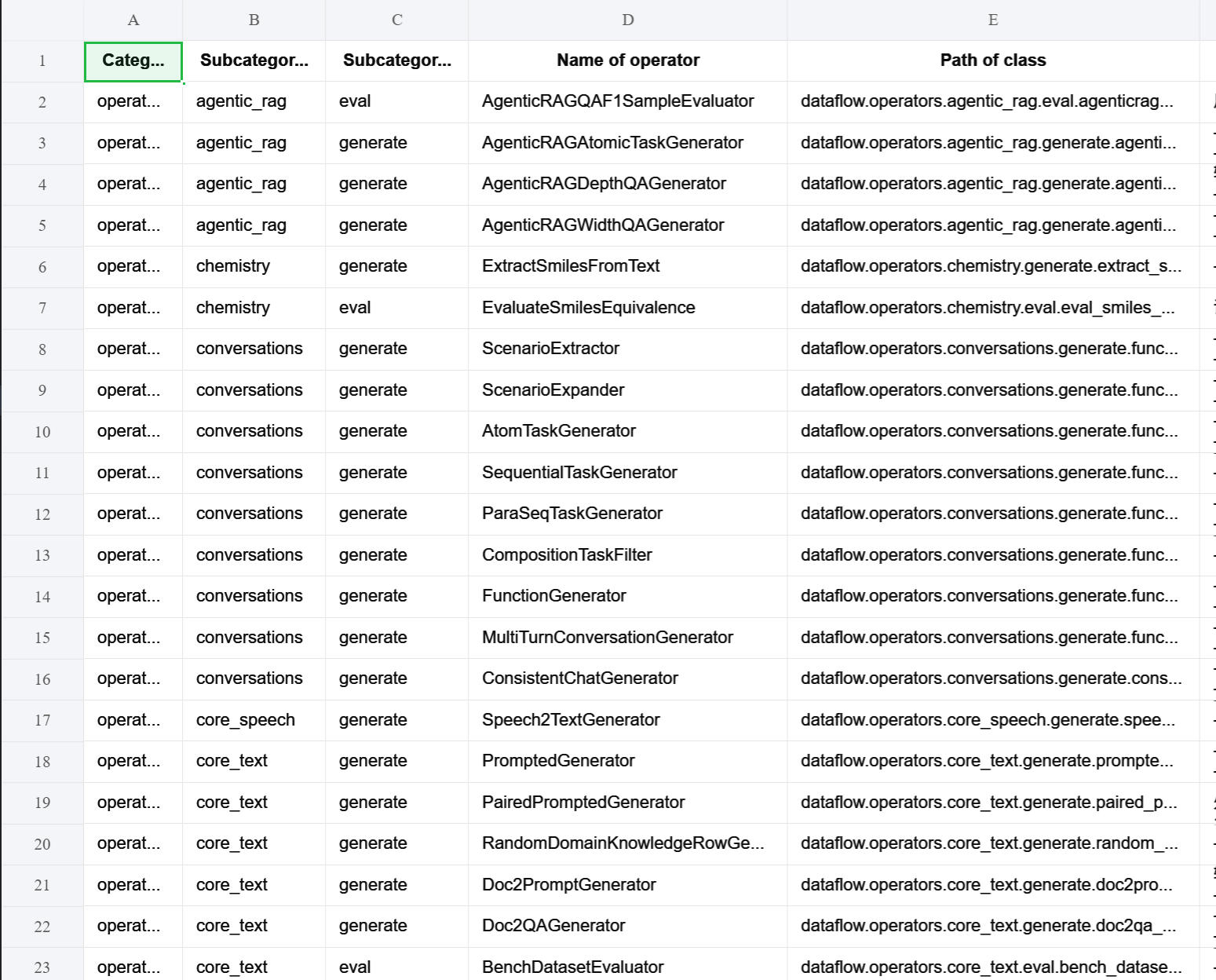
特别的,你可以通过这些Python脚本快速导出Excel表格查看DataFlow目前所有的算子和提示词模板的情况。运行后的结果如下,欢迎试玩:
DataFlow Agent
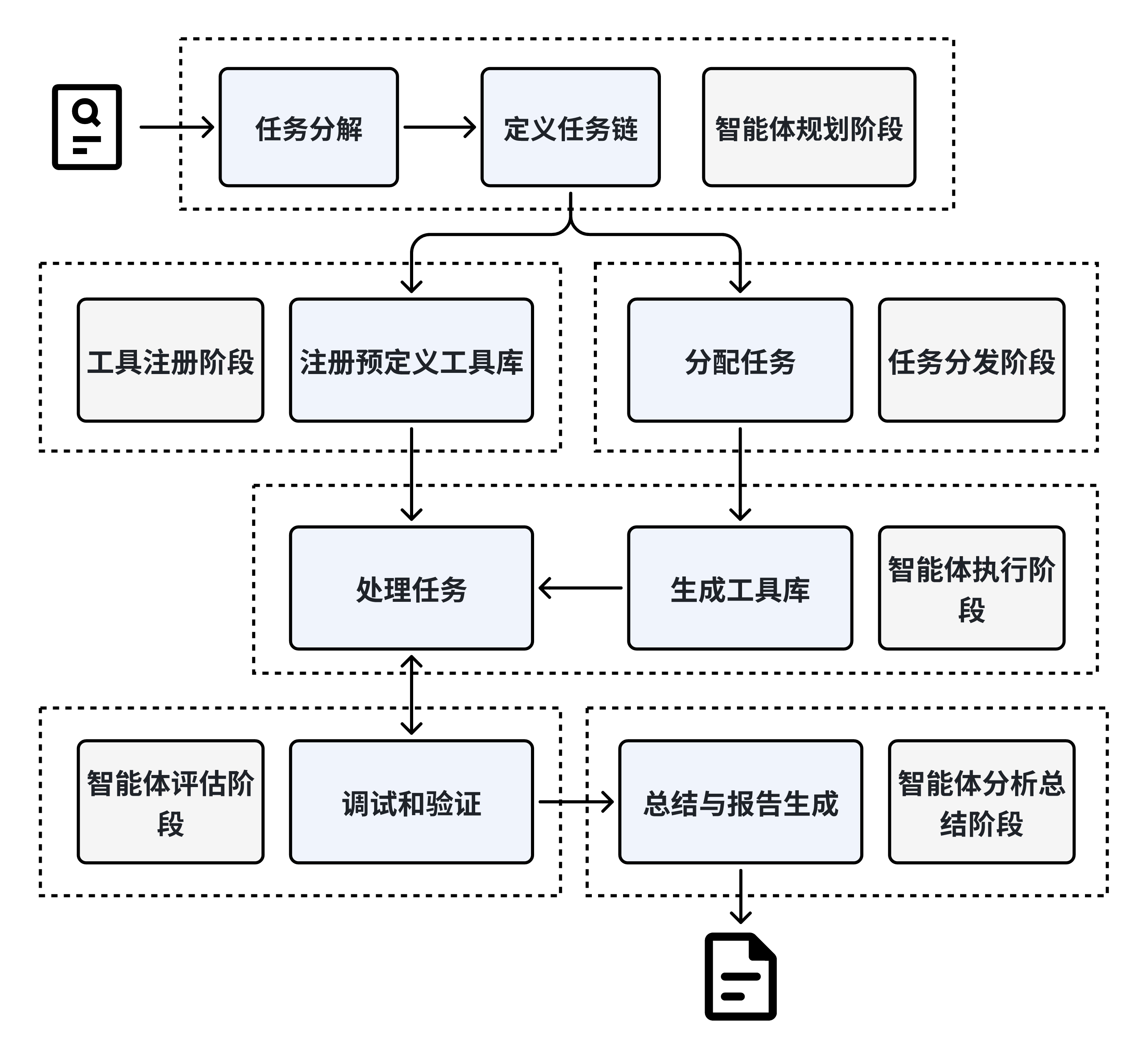
DataFlow Agent 是一个基于多智能体协同的自动化任务处理系统,覆盖 任务拆解 → 工具注册 → 调度执行 → 结果验证 → 报告生成 的完整流程,致力于复杂任务的智能化管理与执行。其核心模块包括:
- Planning Agent:理解用户意图,并将高层需求拆解为具体可执行任务链;
- Tool Register:动态管理已有和新生成的工具(如算子、模型或脚本);
- Task Dispatcher:将任务指派给 Execution Agent,支持代码自动生成与调试;
- Execution Agent:执行具体任务,进行数据处理、模型调用等;
- Evaluation Agent:对执行结果进行质量与正确性评估;
- Analysis Agent:对流程和结果进行总结,生成结构化报告。
系统支持短期与长期记忆机制,能够维持多轮交互状态,在保证标准化流程的同时,具备高度的动态适应能力,尤其适用于数据治理、自动化数据分析等需要多阶段协同的复杂场景。