

快速上手-Ecosystem
概述
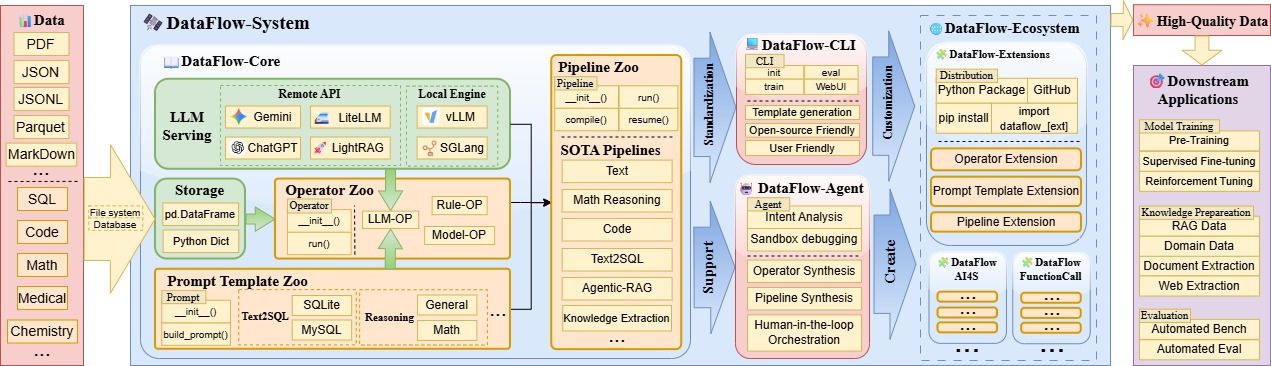
如图所示,DataFlow的图景是:
算子库 + Prompt库 + Pipeline库=<DataFlow-Extension>
- 成熟的算子,提示词和构成的pipeline构成一个又一个DataFlow-Extension,服务于具体的领域和任务。
<DataFlow-Extension> + ... + <DataFlow-Extension> = <DataFlow-Ecosystem>
- 通过Github仓库或者Pypi分发不同的
DataFlow-Extension包含大量面向各种垂域和需求的成熟管线,即可构建完整的DataFlow-Ecosystem。用户可以分发,或者按需组合拿到自己想要的管线。
- 通过Github仓库或者Pypi分发不同的
命令行工具 dataflow init repo
为了更好的供用户构建分发自己的Pipeline和对应的算子库,我们提供了基于命令行的“脚手架”工具来快速生成模板。可以在某个空路径下通过如下命令构建:
dataflow init repo启动该命令后,会有一系列询问来协助你自动构建一个可分发的仓库模板,含义如下:
[1/8] repo_name (my-dataflow-extension): # 整个仓库文件夹的名字
[2/8] package_name (my_dataflow_extension): # Python Package的名字
[3/8] author (Your Name): # 你的姓名,会出现在Readme中和Python的project.toml中
[4/8] description (A DataFlow extension with operator + prompt + pipeline): # 会简要的出现在Readme.md中
[5/8] init_version (0.0.1): # Python包的起始版本
[6/8] Select license # 开源协议
1 - Apache-2.0
2 - MIT
3 - BSD-3-Clause
4 - Proprietary
Choose from [1/2/3/4] (1):
# 默认Python版本,主要是大于等于该版本
[7/8] Select python_version
1 - 3.10
2 - 3.11
3 - 3.12
Choose from [1/2/3] (1):
# 是否生成样例算子,如果是no则只有文件夹结构。
[8/8] Wether include exmaple operator & pipeline & prompt_template files in this DataFlow-extension template?
1 - yes
2 - no
Choose from [1/2] (1):
Applied license: Apache-2.0执行完毕后,会生成完整的仓库。随后可以在仓库根目录下执行
pip install -e .即可本地安装当前的仓库,并且所有修改都可以直接生效于这个包。
此外,执行如下命令即可立马初始化默认的Github仓库,以供后续发布使用。
git init
git add .
git commit -m "Initial commit"使用DataFlow-Extension的仓库
为了方便后续介绍,我们假设我们安装后的Extension的Python包名是df_123
和DataFlow主仓库的Lazyload算子不同的是,DataFlow-CLI生成的仓库,会默认扫描df_123/operator路径下的所有算子并将其import,此时这些算子会被注册在DataFlow主仓库的注册机中。
如果你想查看这些新算子在注册机中的情况,通过如下脚本即可查看:
# 主仓库注册机
from dataflow.utils.registry import OPERATOR_REGISTRY
# import,新的Extension仓库,这一步会导入所有注册过的算子
import df_123
# 正常执行,Extension的算子会出现在这里。
print(OPERATOR_REGISTRY._obj_map.keys())这样扩展包即和DataFlow主仓库有机的协调在一起了。实现了即插即用的拓展。经过Github和Pypi分发后,相应的流水线的使用和体验会变的非常方便,构建了一整套基于DataFlow的生态系统。