WebUI 教程
这一页按真实操作顺序介绍如何通过 WebUI 使用 LoopAI。建议把它理解为一条完整上手路径,而不是一组分散功能说明。
教程顺序
WebUI 的建议学习顺序是:
- 先准备
starter.yaml - 启动 WebUI 服务
- 在
Config中补全全局参数 - 使用资源池管理维护路径类参数
- 创建任务并进入任务面板
- 回到任务面板,通过对话进入不同 Agent 执行任务
- 观察节点状态、消息与结果
第一步:准备 starter.yaml
在启动 WebUI 之前,先在仓库根目录放好 starter.yaml:
cp examples/config/starter.yaml ./starter.yaml这里至少要保证 Starter 本身可以工作。否则系统刚启动时就会缺少基础模型配置。
第二步:启动 WebUI
如果还没有准备前端发布产物,先执行:
python scripts/download_ui_release.py然后启动后端:
python api/start.py默认地址:
http://localhost:8855第三步:先配置全局参数
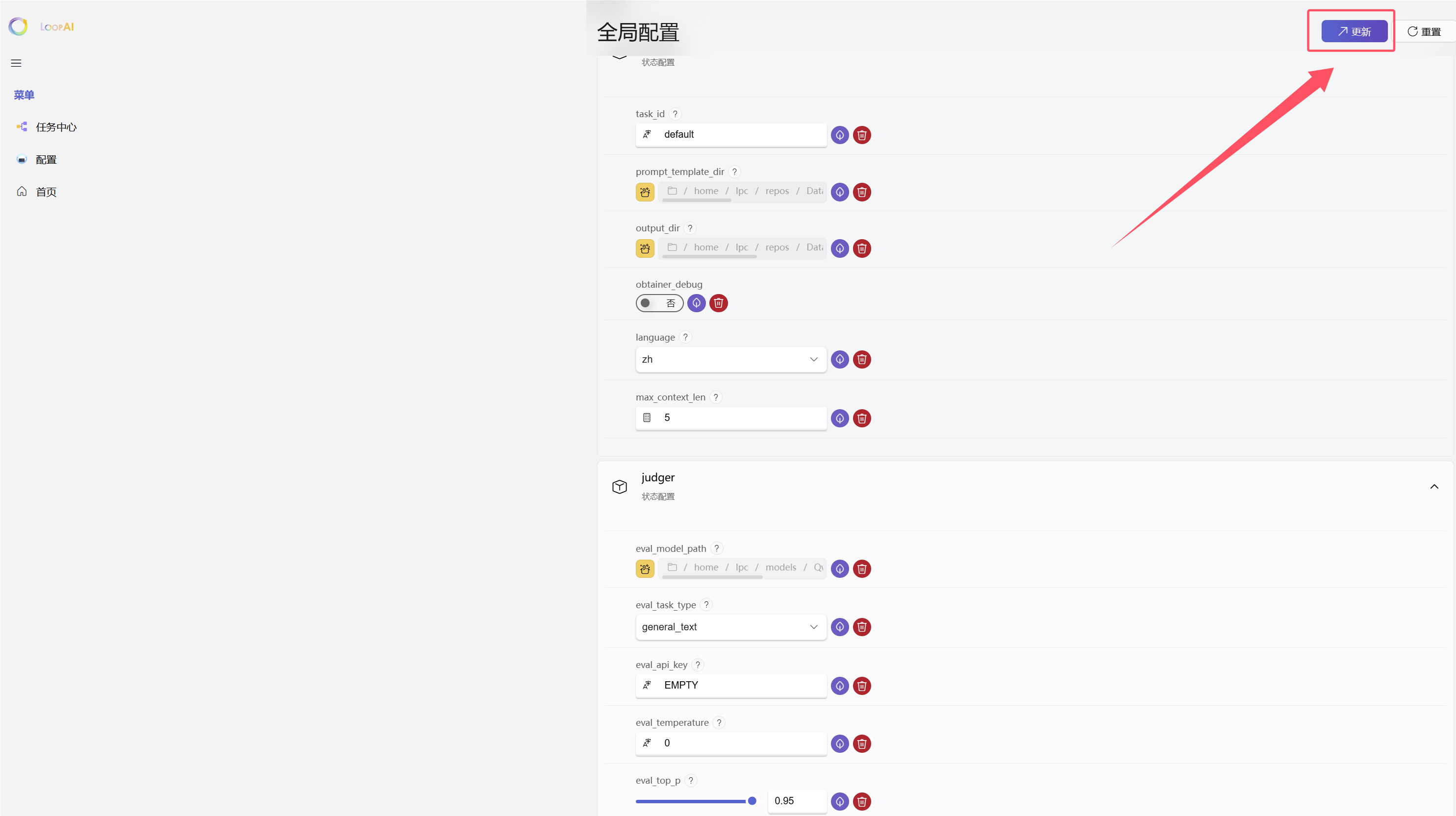
第一次上手时,不建议一打开界面就立刻执行评测或分析。更稳妥的顺序,是先去 UI 里的 Config 面板把全局参数补齐,再开始真正的任务流。
这样做的原因很简单:
- 后续很多 Agent 都依赖这些全局参数
- 如果基础配置没补齐,系统很快就会跳去
ConfigerAgent让你补字段 - 先把全局参数整理好,后面的操作会顺很多
这里有两个非常重要的使用规则:
规则 1:参数修改通常要到下一轮才生效
在 LangGraph 里,任务启动后,运行中的状态并不是任意时刻都能即时重写。当前阶段下,很多参数修改需要到下一轮流程里才会真正反映。
目前最稳妥的方式是:
- 通过对话修改参数
- 或在合适的暂停点更新配置,再继续下一轮
规则 2:改完参数后要点右上角 Update
在 Config 里填完全局参数之后,需要点击右上角的 Update,否则配置不会正式写回当前任务上下文。
另外,每个参数项右上角通常还有一个 ?,里面会给出该参数的说明和使用提示。第一次配置时,建议优先点开查看,能减少很多试错成本。
第四步:使用资源池管理维护路径类参数
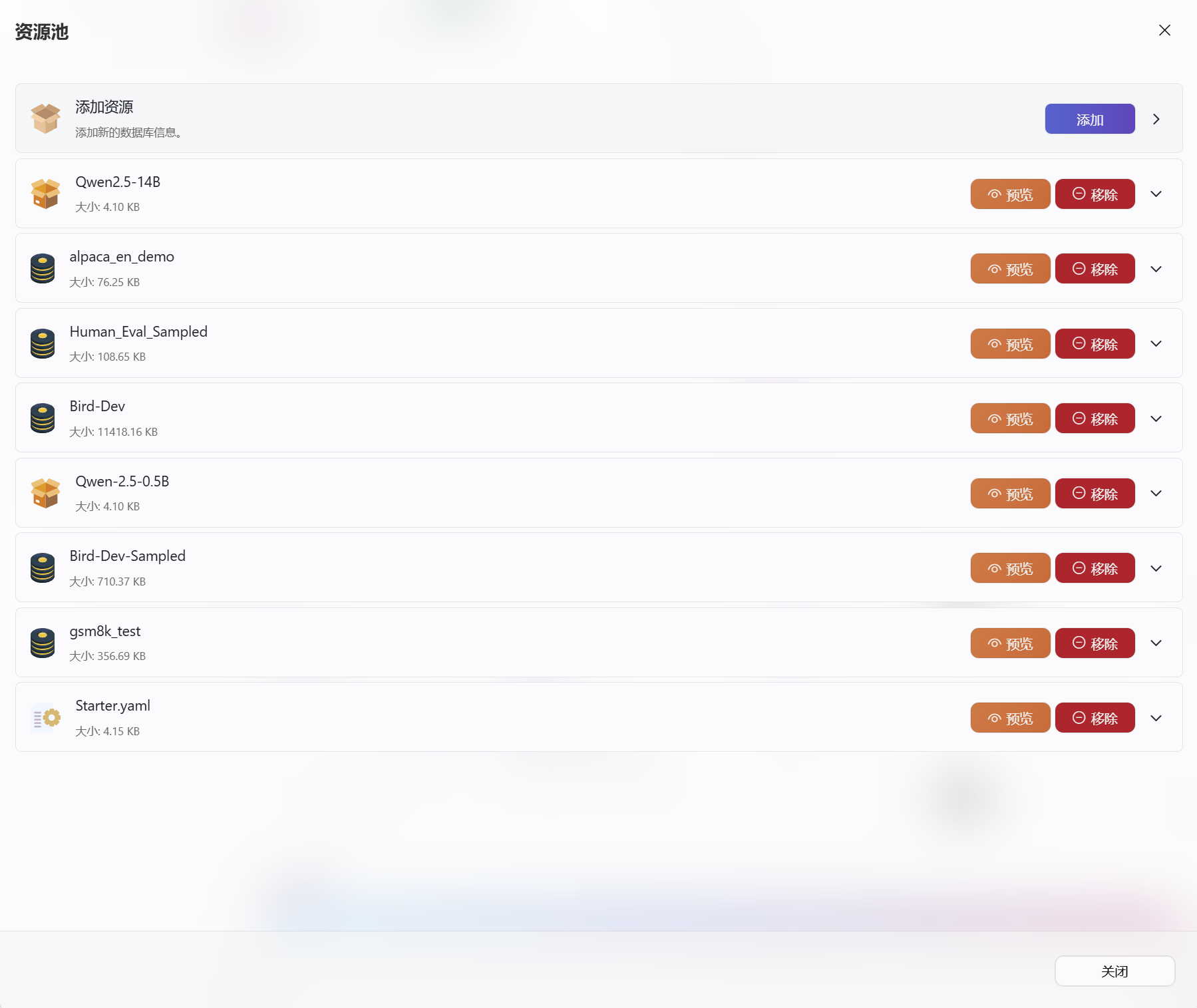
针对模型、数据集、配置文件等路径类信息,推荐优先使用“资源池管理”。
这样做的好处是:
- 后续配置路径时可以快速选择
- 减少手工输入路径出错
- 便于统一管理模型和数据资源
这一步不是强制的,但非常建议在正式开始任务前先整理好。
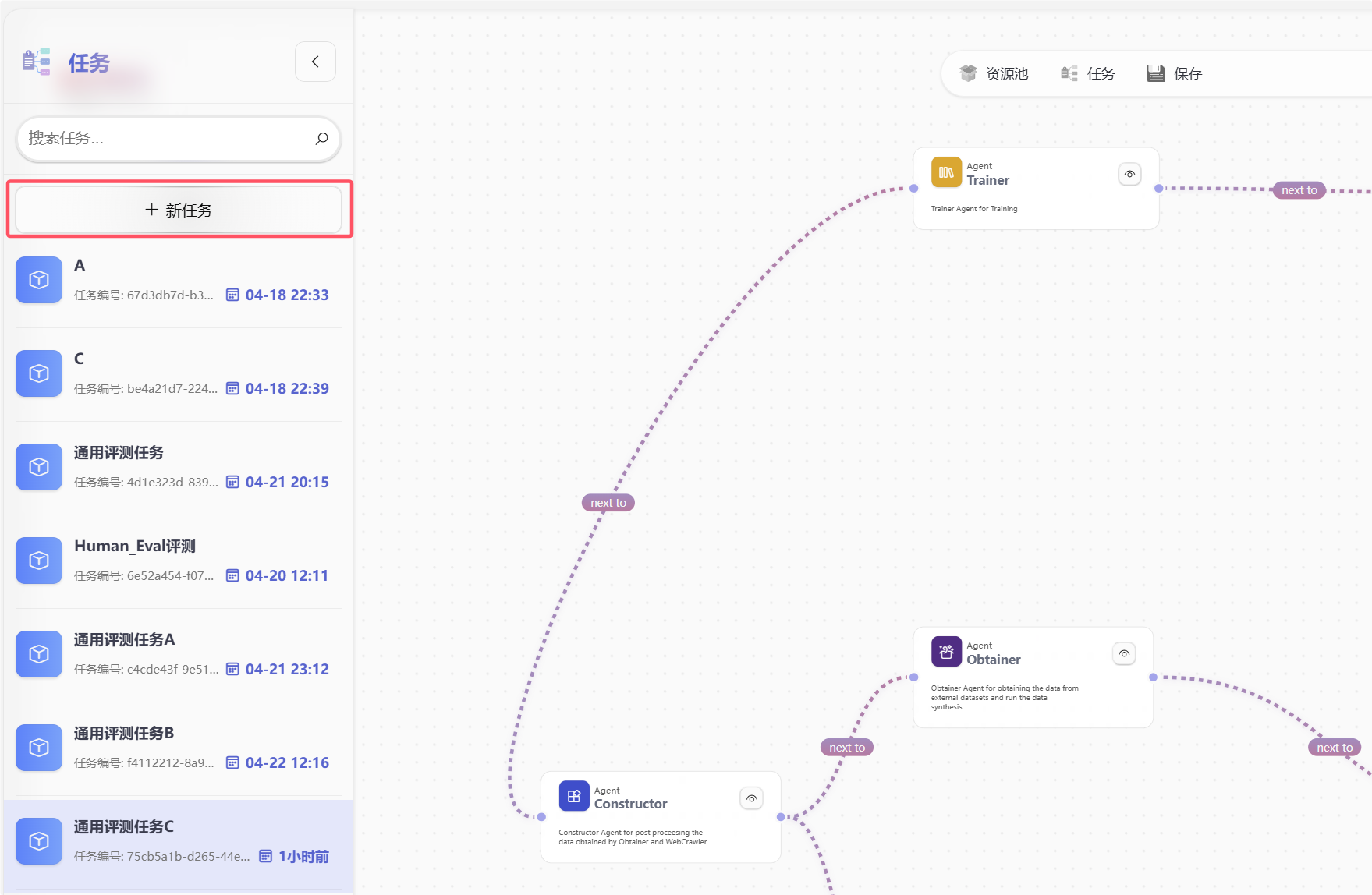
第五步:创建任务并进入任务面板
完成全局参数和资源池整理之后,再打开任务面板,创建一个新任务,然后点击“运行”。
这时可以把任务理解成“已经具备了进入执行流的基础条件”,接下来再开始通过对话驱动具体 Agent,会比一上来就边跑边补配置更清晰。
点击启动后可以稍作等待。通常要等到节点上开始出现状态字段,才表示这次任务启动成功,系统已经进入可继续交互的状态。
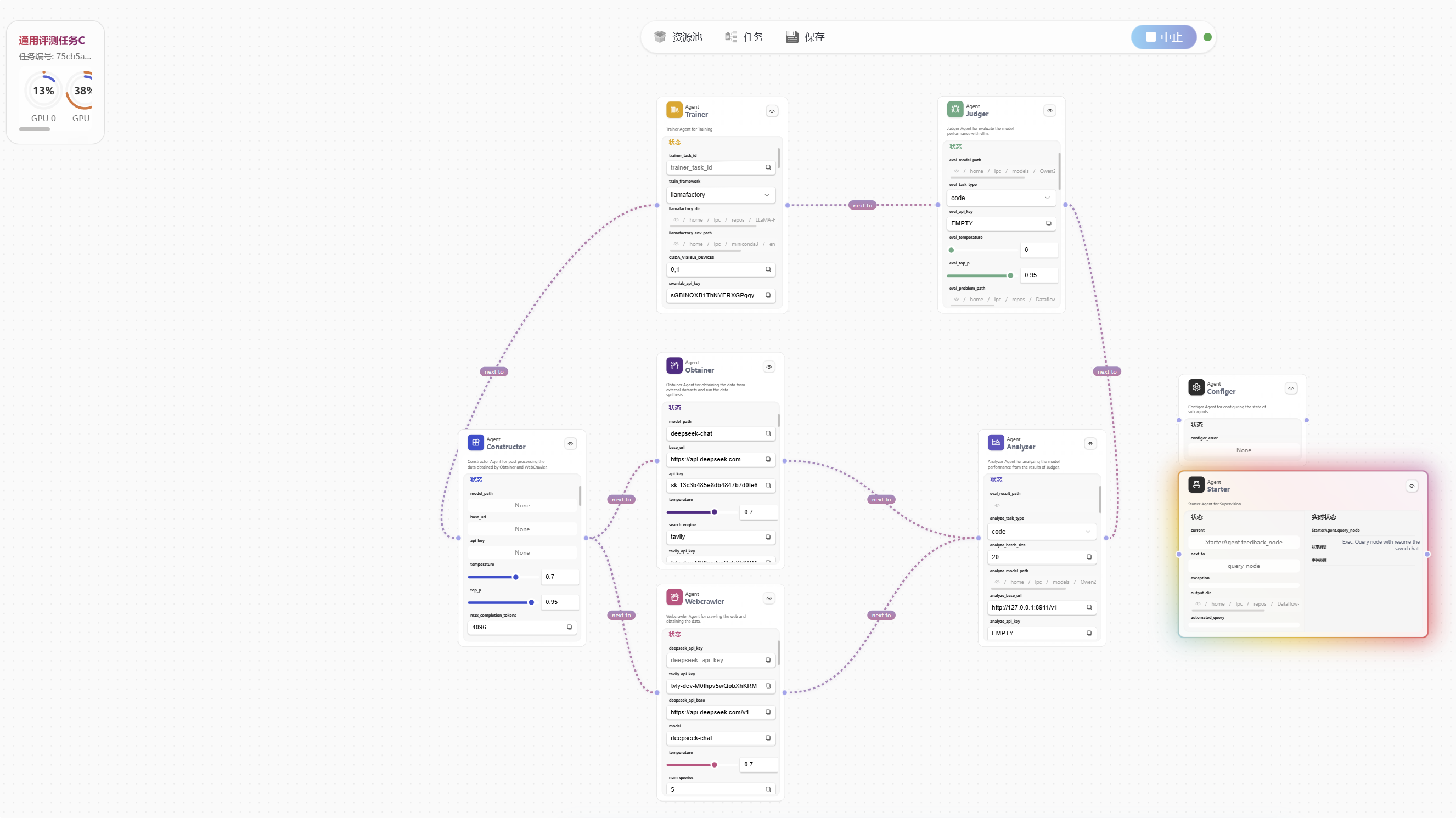
第六步:回到任务面板,通过对话驱动流程
完成全局参数和资源池整理之后,再回到任务面板,通过对话驱动 LoopAI 进入不同 Agent。
这时任务启动后,首先真正与你交互和调度流程的,是 StarterAgent。它是整个系统的主管 Agent,主要负责:
- 与你对话
- 理解当前任务意图
- 决定接下来要跳转到哪个 Agent
- 在不同子 Agent 之间衔接流程
因此这里再介绍 Starter 会更自然:你已经先配好了全局条件,接下来才轮到它接管流程并把任务送往具体执行节点。
例如你可以输入:
请进入configer配置judger的eval_task_type为code此时系统会尝试进入 ConfigerAgent 来帮助你补全参数。
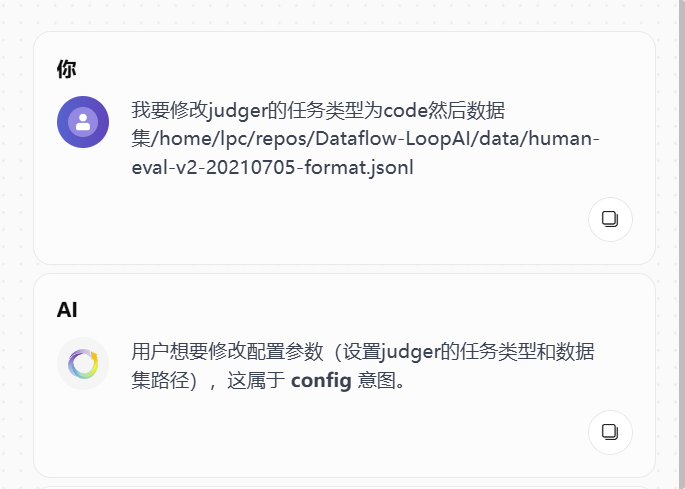
如何判断参数是否真的修改成功
这是 WebUI 里最容易误判的地方之一。
当 Agent 询问你参数信息时,你可以继续确认或修改,但要注意:
- 不是看到对话回复就算修改成功
- 要等到 tool 信息框结束
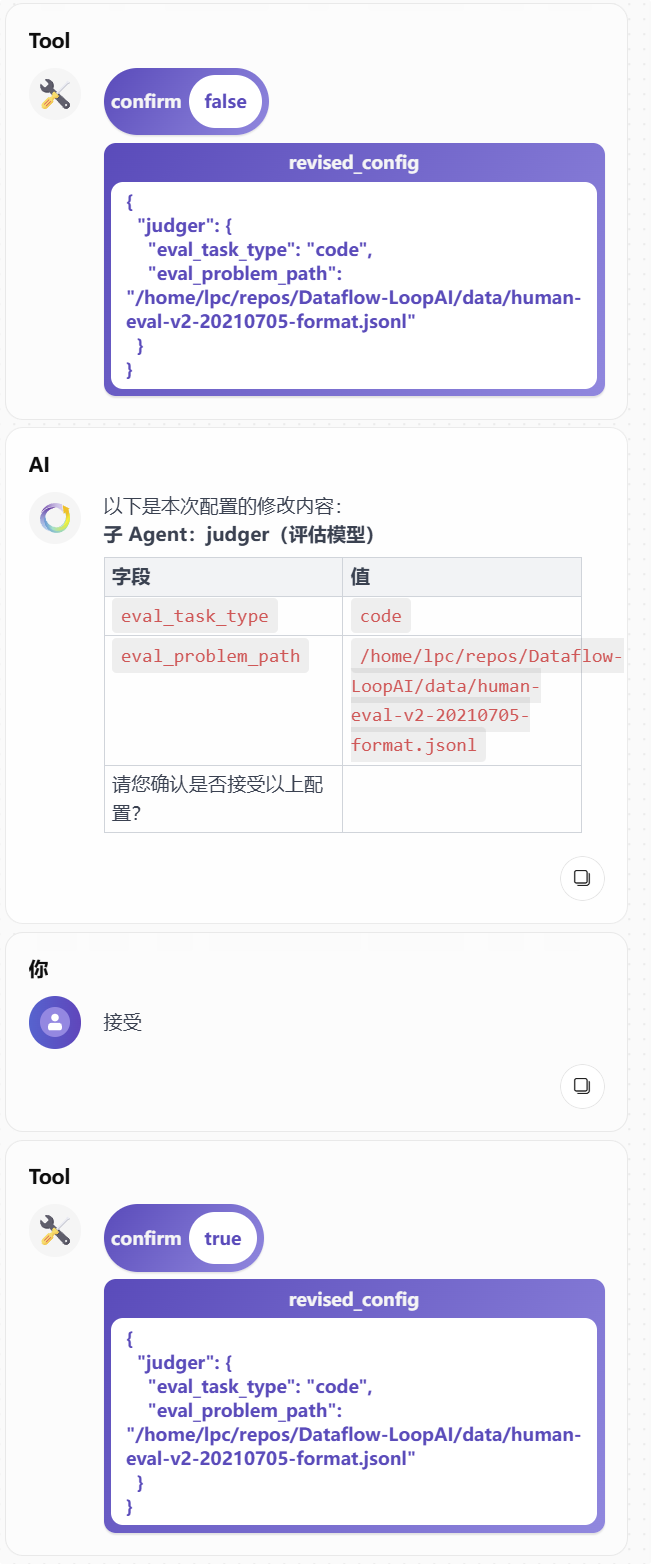
- 并且看到
confirm: true
只有出现 confirm: true,才表示本次配置写入成功。
同时,你还可以观察:
- flow 图上对应 Agent 的状态字段是否更新
- 左侧状态中对应值是否发生变化
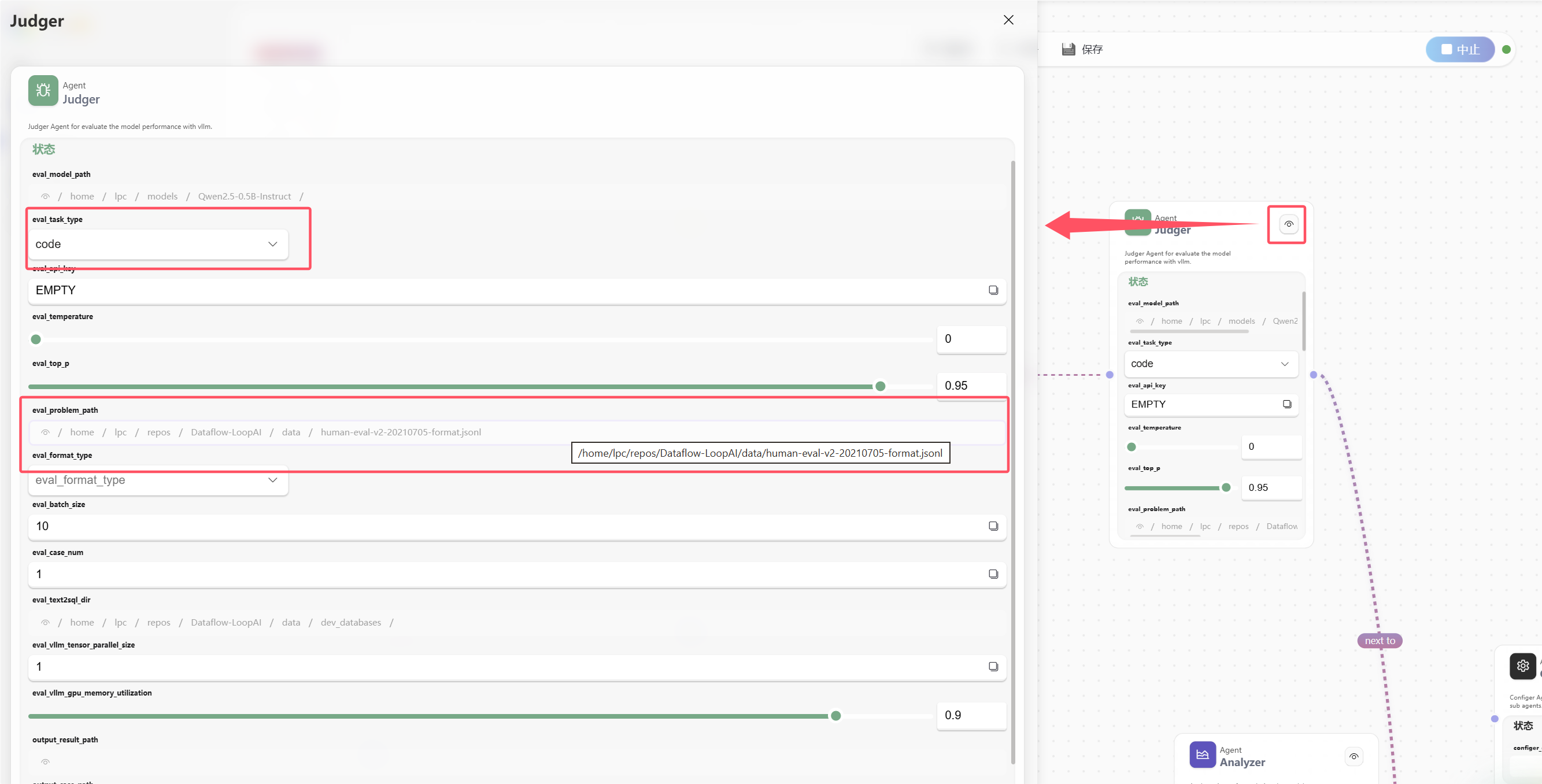
如何判断当前正在谁的节点里
有两种最直接的方法:
- 看 tool message 里的
next_to - 看 flow 图上哪个 Agent 节点下方有亮光
这两个信号通常能帮助你判断系统刚刚从 Starter 跳到了谁,或者下一步准备跳去谁。
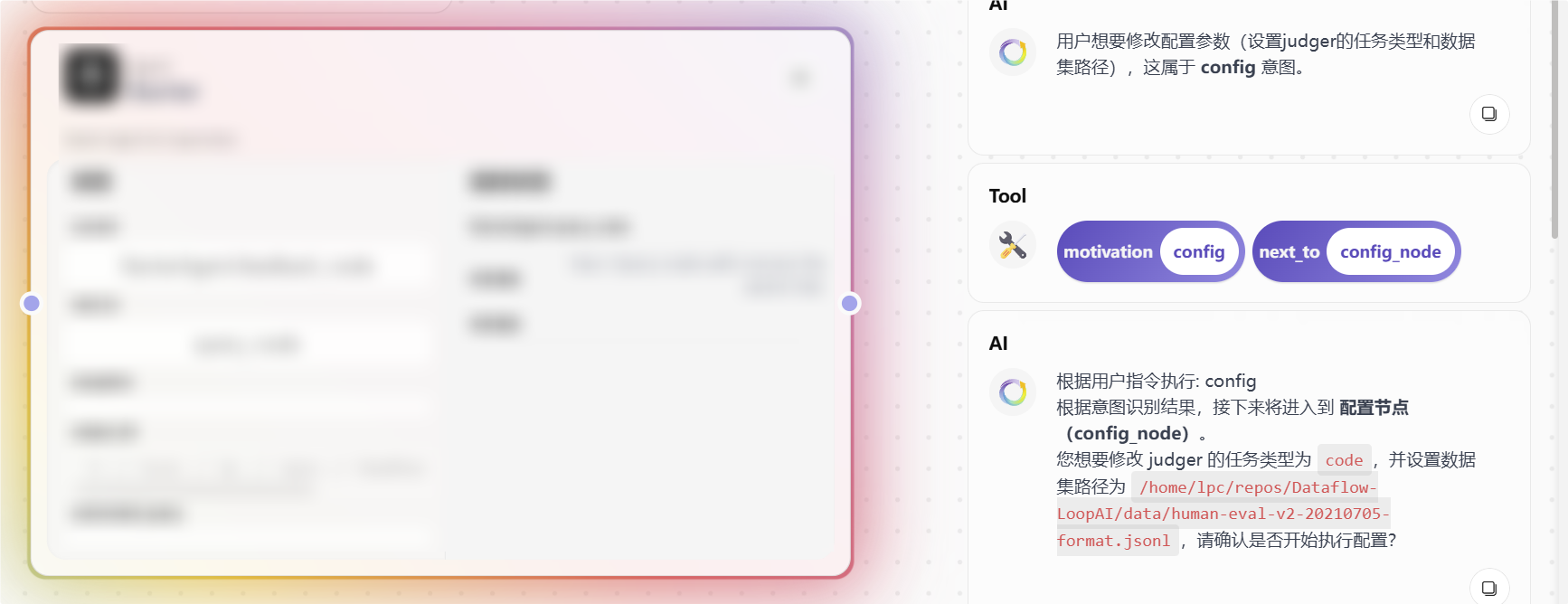
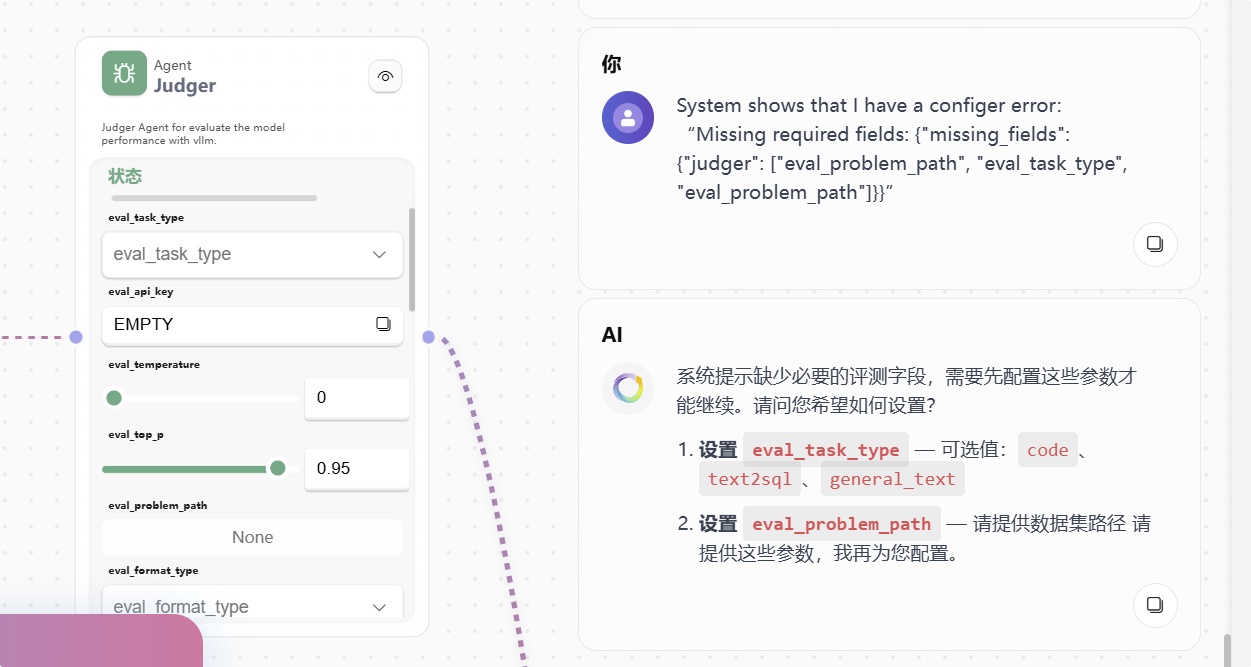
如果缺参数,LoopAI 会怎么处理
当你尝试启动某个 Agent,例如直接说“开始评测”时,LoopAI 会先检查当前所需参数是否齐全。
如果参数缺失,常见行为是:
- 系统自动跳转到
ConfigerAgent - 引导你补全缺失字段
- 补完后询问你是否继续
- 继续后回到刚才中断的节点
这也是为什么 Starter 更像主管,而不是固定执行器。
第七步:观察节点状态、消息与结果
执行某个 Agent 任务时,右侧 Custom Info 往往会更接近实时信息源,你可以在那里看到:
- 当前进度
- 实时消息
- 执行中的关键状态
而左侧 States 并不一定实时更新。很多字段会在该阶段执行完成后才集中刷新。
对于路径类更新字段,如果界面支持点击预览,可以直接点击查看对应内容。
示例一:启动评测与分析
1. 创建任务并点击运行
运行后可以看到 state 已经加载完成。
2. 发起评测任务
如果此时 Judger 的 eval_model_path 为空,不需要立刻退出页面手动找配置。
你可以直接通过对话告诉系统要补什么,LoopAI 会协助你进入配置流程并补齐参数。
3. 执行评测
参数齐全后,就可以开始评测。
在一些本地评测场景下,系统会启动本地 vLLM 来执行模型推理任务。
评测过程中你可以查看:
- 左上角面板中的 GPU 使用情况
- 节点详情里的监控界面
4. 查看评测结果
评测完成后,在左侧面板中通常可以查看:
- 模型样例输出
- 对应评测结果
5. 进入分析阶段
接下来可以对话启动分析任务。
如果分析器所需的评测结果路径为空,但你刚刚已经完成评测,系统通常会自动补齐相关字段。
如果此前没执行评测,也可以手动通过对话补参数。
6. 执行分析
分析阶段通常更适合使用更强的模型,因此你可能需要:
- 提前启动外部 vLLM 服务
- 或配置其他模型 API
分析完成后,系统会生成分析报告,你可以在界面中查看详细结果。
示例二:数据获取、后处理与训练
1. 启动 Obtainer
基于分析报告,可以进一步执行 ObtainerAgent 做数据获取。
当前数据获取常见有两类路径:
ObtainerWebCrawler
2. 进入 Constructor
拿到数据之后,可以进入 ConstructorAgent 做数据后处理。
这一阶段通常包括:
- 数据清洗
- 数据合成
- 去重与筛选
目标是减少无效样本和潜在数据泄露风险。
3. 查看处理进度
Constructor 执行过程中,右侧聊天框通常会展示:
- 数据处理进度
- 数据合成过程
- 结果概览
4. 启动 Trainer
数据准备完成后,就可以执行 Trainer 做训练。
当前教程里最重要的可用路径是:
- 基于 Llama-Factory 的 SFT
因此如果要进入训练阶段,请提前准备好训练环境与相关路径配置。
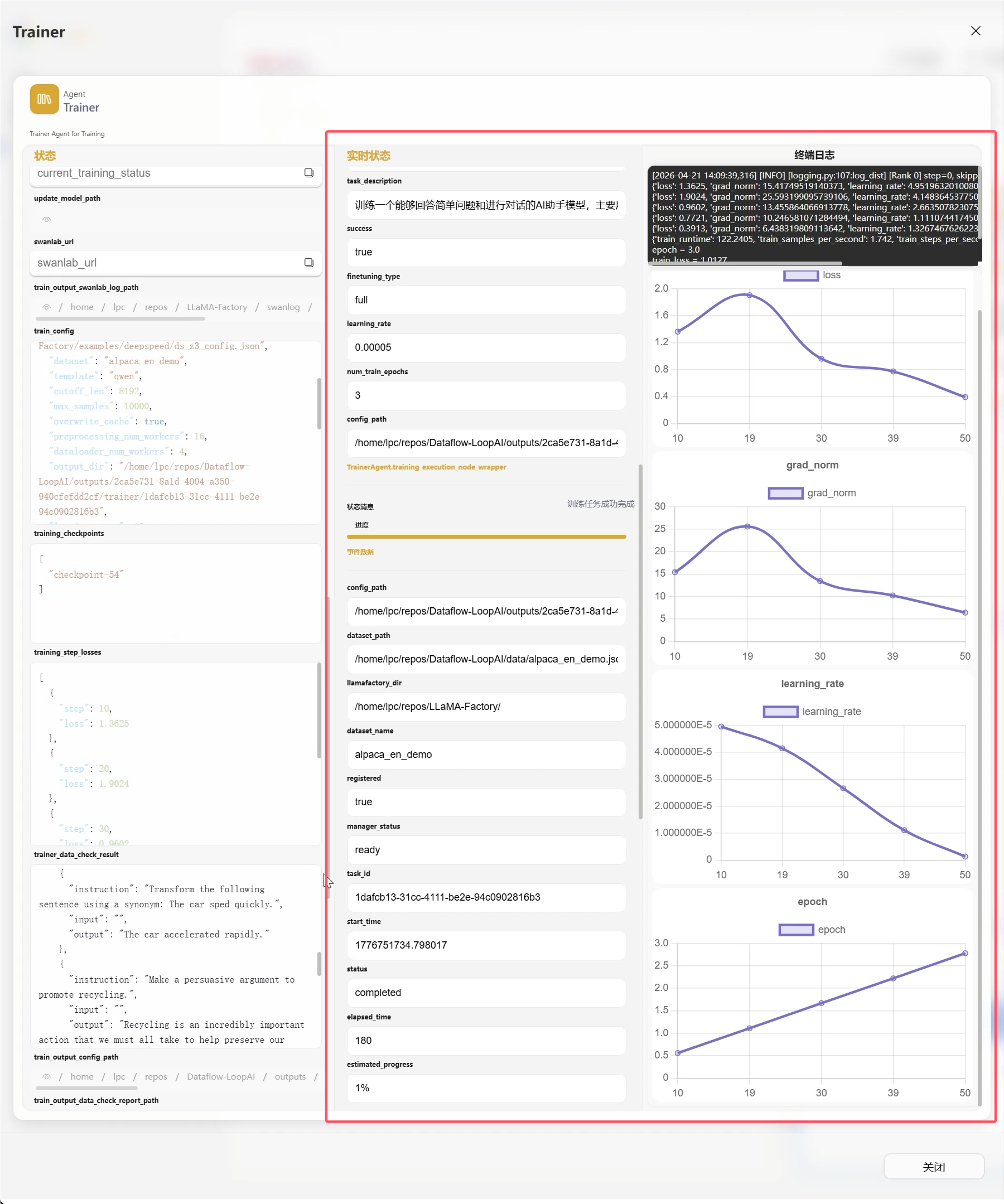
5. 观察训练过程
训练期间,节点面板通常会实时展示:
- 终端日志
- 训练状态曲线
便于监控训练进展。
训练完成后,可以查看详细训练日志,并基于训练产物开展下一轮评测。
一页总结
第一次用 WebUI 时,最重要的不是记住所有 Agent 的名字,而是记住这条使用节奏:
- 先让 Starter 跑起来
- 先补全全局参数
- 参数不够时交给 Configer 补
- 通过对话驱动进入具体 Agent
- 用
next_to、节点亮光、Custom Info 和 States 判断当前执行位置与结果